-
[최적화] Optimal Brain Damage 논문 리뷰최적화 2023. 10. 17. 23:16반응형
들어가기 전에...
https://proceedings.neurips.cc/paper/1989/hash/6c9882bbac1c7093bd25041881277658-Abstract.html
1989년
Yann Le Cun, John S. Denker and Sara A. Solla AT&T Bell Laboratories, Holmdel, N. J. 07733
Part of Advances in Neural Information Processing Systems 2 (NIPS 1989)
무려 30년 전에 모델 경량화에 대해 제안한 논문이다. 물론 주 목적이 경량화였는지, 일반화였는지는 읽어봐야 알겠지만 이런 아이디어를 생각하게 된 논리적인 생각의 흐름이 궁금하다. 논문도 짧고 명확해 보이기 때문에 경량화 공부를 시작할 때 읽으면 좋을것 같다. 또한, pruning의 근간이 되는 논문이라 생각되는데, 참고할 수 있는 글이 없어서 많은 사람들에게 도움이 됐으면 한다. 논문 읽고 구현까지 해보면 좋을 듯 하다. pruning의 개념이 한번에 이해될 듯 하다.
파랑색 글씨는 내가 보충한 내용 + 생각한 내용
빨강색 글씨는 아직 이해중인 내용
Abstract
본 논문에서는 신경망 모델의 크기를 조정하기 위한 아이디어를 제안하였다. 네트워크 내에서 중요하지 않은 가중치를 제거함으로써 다음과 같은 향상을 기대할 수 있다.
- better generalization
- fewer training examples required
- improved speed of learning and/or classification
기본적인 아이디어는 second-derivative information을 사용하여 네트워크 복잡성과 training set error를 절충하는 것이다.
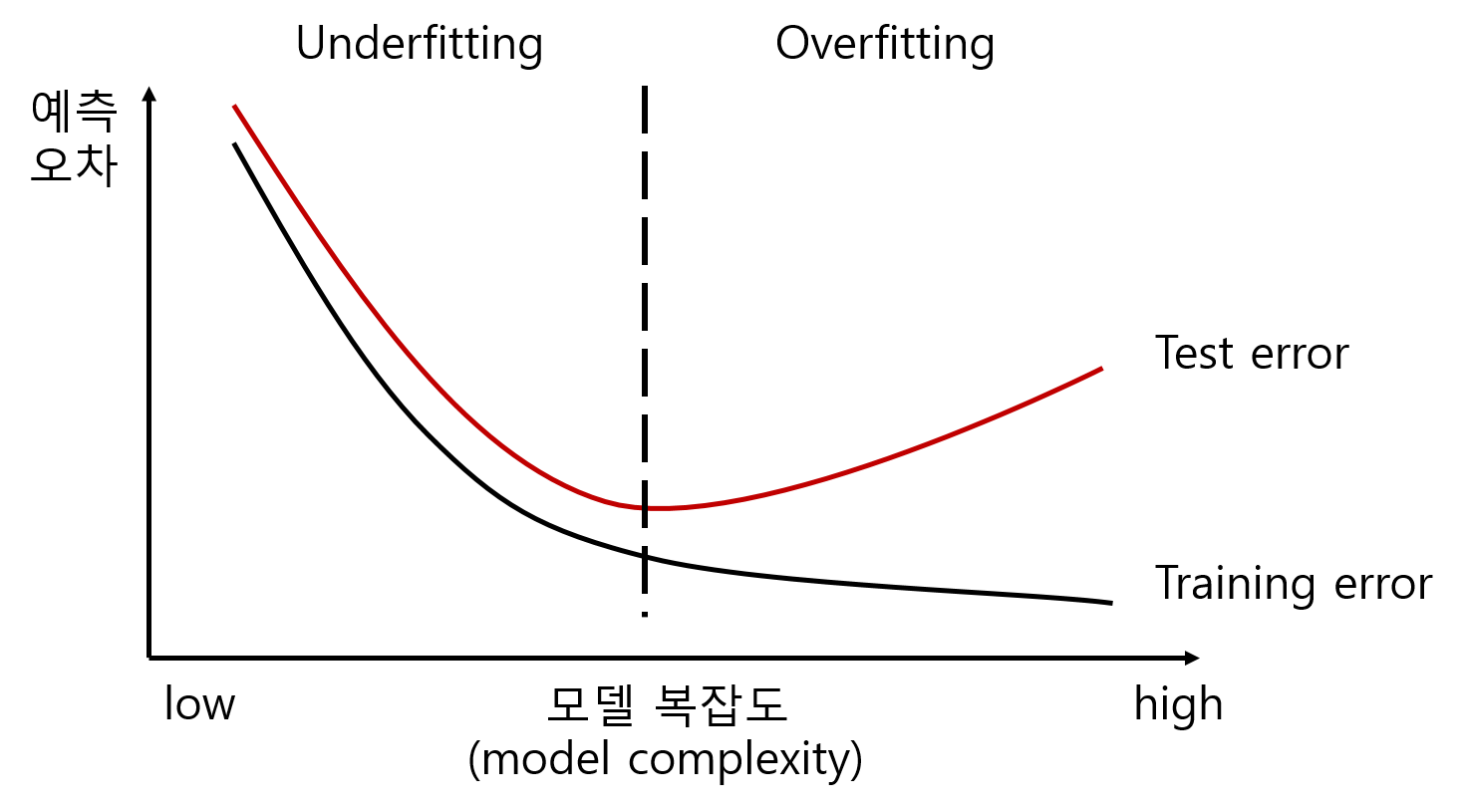
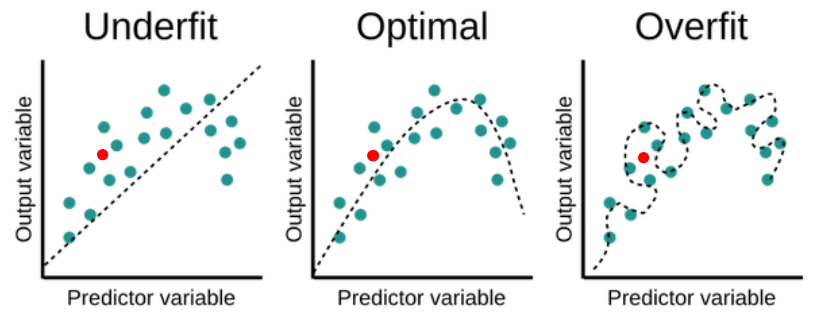
- 일반적으로 모델이 복잡해질수록 학습 데이터에 대한 error와 test 데이터에 대한 error 모두 줄어들지만, 임계값이 넘어가는 순간 test 데이터에 대한 error가 다시 증가하게 된다. 따라서 이 임계값을 찾는 것이 매우 중요하다.
실험을 통해 제안 아이디어가 실제 활용이 가능하다는 것을 보인다.
1 INTRODUCTION
최근 real-world 문제를 해결하기 위해서는 구조화된 큰 네트워크가 사용되었다. Application이 복잡해짐에 따라 네트워크는 점점 더 구조화되고 커지게 될 것이다. 이에 따라 아키텍처를 비교하고 네트워크 크기를 최소화하는 방법이 필요할 것이다. 더 중요한 것은 파라미터의 수가 증가할 수록 과적합 문제로 인해 일반화 성능에 매우 큰 영향을 미칠 수 있다. 따라서 본 논문에서는 가중치를 선택적으로 삭제하여 학습 네트워크 크기를 줄이기 위한 OBD(Optimal Brain Damage)라는 기술을 제안하였다. OBD는 네트워크를 최소화 하는 절차이자 더 나은 아키텍처를 제안하기 위한 interactive tool이다.
OBD의 기본 아이디어는 다음과 같다.
- take a perfectly reasonable network
- delete half (or more) of the weights
- wind up with a network that works just as well, or better
일반적으로 학습 데이터에 비해 많은 파라미터를 가진 네트워크는 잘 일반화되지 않는다. 반면 너무 적은 파라미터를 가진 네트워크는 데이터를 표현하기에 충분하지 않다.
이 tradeoff에 도달하기 위한 한 가지 방법은 일반적인 training error와 some measure of the network complexity로 구성된 cost function 를 최소화 하는 것이다.
- cost function, loss funcion, objective function은 미묘한 차이가 있다.
- loss funcion : 하나의 input data에 대한 오차를 계산하는 함수
- cost function : input dataset에 대한 오차(=cost)를 계산하는 함수 (=loss function의 평균값)
- objective function : 학습을 통해 최적화 시키려는 함수 (cost funcion외의 function들도 포함될 수 있음.)
- 위의 개념에 따르면 앞서 언급한 cost function은 사실 objective function의 개념이다.
이와 관련되어 몇 가지 연구가 진행되었다.
Vapnik-Chervonenkis dimensionality, description length와 같이 복잡성 측정에 대해 다양한 방법이 제안되었다. 전통적으로 0이 아닌 파라미터의 수가 복잡성의 측정값을 대표했었다.
기존 통계에서는 파라미터를 삭제하는 순서가 미리 설정되어 있었다. 예를 들어, 다항식에서 smoothness heuristic은 고차항을 먼저 삭제해야 한다. 하지만, 신경망에서는 파라미터 삭제 순서를 정의하기 어렵다.
간단한 방법은 "saliency"이 작은, 즉, 삭제를 하더라도 train error에 가장 적은 영향을 미치는 파라미터를 삭제하는 것이다. 삭제 후에는 네트워크를 다시 학습해야 하며, 반복적으로 파라미터를 삭제할 수 있다 (이때, weight-decay를 사용한다). 실제로 여러 네트워크 최소화 scheme는 non-proportional weight decay 혹은 gating coefficients를 사용하여 구현되었다. 일반화 성능은 작은 trainset에서?? 크게 향상된 것으로 확인되었다. 하지만 이 방법에는 2가지 단점이 존재한다.
- catastrophic effects를 피하기 위해 pruning 이후, fine-tuning이 필요한 것
- 학습 과정이 매우 느려지는 것
또한, 이 방법에는 "네트워크 복잡성 = 네트워크의 파라미터 수" 라는 가설을 포함한다.
본 논문의 요점 중 하나는 "magnitude equals saliency"는 근사치를 넘어, 이론적으로 정당한 saliency 측도를 제안하는 것이다. 우리는 파라미터에 대한 objective function의 second derivative를 사용하여 saliency를 계산한다. 이 방법은 backpropagation으로 학습된 손으로 쓴 숫자 인식 네트워크를 사용하여 검증하였다 (Back-Propagation Applied to Handwritten Zipcode Recognition).
2 OPTIMAL BRAIN DAMAGE
Objective function을 중심으로 모델이 학습되기 때문에, 파라미터를 삭제함으로써 발생하는 objective function의 변화로 해당 파라미터의 saliency를 정의하는 것이 합리적이다. 하지만, 이렇게 saliency를 측정하는 것은 매우 어렵다. (각 파라미터를 일시적으로 삭제하고, objective function 변화를 측정하여 saliency를 평가하는 것)
다행히 error function의 local model을 구성하고 파라미터 vector의 교란 효과를 분석적으로 예측할 수 있다. 우리는 objective function $\E$를 Taylor series로 근사화 한다 (미지의 함수를 근사 다항함수로 표현하는 것). 파라미터 vector의 perturbation $\delta U$는 objective function을 다음과 같이 변경한다.
$$\mathbf{\delta E=\sum_{i}g_{i}\delta u_{i}+\frac{1}{2}\sum_{i}h_{ii}\delta u_{i}^{2}+\frac{1}{2}\sum_{i\neq j}h_{ij}\delta u_{i}\delta u_{j}+O(\left\|\delta U \right\|^{3})\cdots\cdots\cdots\cdots(1)}$$
- $\delta u_{i}$ : $\delta U$의 구성 요소
- $g_{i}$ : U에 대한 E의 기울기 G의 구성 요소
- $h_{ij}$ : U에 대한 E의 Hessian matrix H의 요소
$$\mathbf{g_{i}=\frac{\partial E}{\partial u_{i}}\quad and \quad h_{ij}=\frac{\partial^{} E}{\partial u_{i}}\cdots\cdots\cdots\cdots(2)}$$
삭제될 때, E를 가장 적게 증가시키는 파라미터 집합을 찾는 것이 목표이다. 하지만 이는 matrix H가 매우 커서 (2600개의 파라미터에 대해 6.5 x 106 항이 존재함) 계산하기가 매우 어렵다. 따라서 어느정도 근사가 필요하다.
- "diagonal" approximation는 여러 파라미터를 삭제함으로써 발생되는 $\delta E$이 각 파라미터를 삭제함으로써 발생되는 $\delta E$의 합이라고 가정한다. cross term은 무시되므로 식 (1)에서의 세번째 항은 버려진다.
- "extremal" approximation는 학습이 수렴한 이후에 파라미터 삭제가 수행될 것이라고 가정한다. 그러면 파라미터 vector는 E의 (local) minumun에 있고, 식 (1)에서의 첫번째 항은 버려진다. 또한, local minimun에서 모든 $h_{ii}$는 음수가 아니기 때문에 모든 파라미터의 perturbation는 E를 증가시키거나 유지시킨다.
- "quadratic" approximation는 식 (1)의 마지막 항을 무시할 수 있을 정도로 cost function이 거의 quadratic이라고 가정한다.
이 가정에 따르면 식 (1)은 다음과 같다고 가정할 수 있다.
$$\mathbf{\delta E=\frac{1}{2}\sum_{i}h_{ii}\delta u_{i}^{2}\cdots\cdots\cdots\cdots(3)}$$
2.1 COMPUTING THE SECOND DERIVATIVES
diagonal second derivatives를 계산하는 효율적인 방법이 필요하다.
objective function을 MSE(Mean-Squared Error)라고 가정한다. 아래 수식은 하나의 input 데이터에 대해 적용된다. 이후 E와 H는 학습 데이터에서 평균을 구해야 한다. 네트워크 상태는 표준 공식을 사용하여 계산한다.
$$\mathbf{x_{i}=f(a_{i})\quad and \quad a_{i}=\sum_{j}w_{ij}x_{j}\cdots\cdots\cdots\cdots(4)}$$
- $x_{i}$ : unit i의 상태
- $a_{i}$ : total input (weighted sum)
- f : squashing function (=activation function)
- $w_{ij}$ : unit i에서 unit i로 가는 connection
shared-weight 네트워크에서 하나의 파라미터 $u_{k}$sms 하나 이상의 connection을 제어할 수 있다. $w_{ij} =u_{k}$ for all $(i,j) \in V_{k}$, $V_{k}$는 index 쌍의 집합이다. 연쇄법칙에 의해 H diagonal 항은 다음과 같이 주어진다.
$$\mathbf{h_{kk}=\sum_{(i,j)\in V_{k}}\frac{\partial ^{2}E}{\partial w_{ij}^{2}}\cdots\cdots\cdots\cdots(5)}$$
우변의 수식은 식 (4)에 의해 아래와 같이 표현할 수 있다.
$$\mathbf{\frac{\partial ^{2}E}{\partial w_{ij}^{2}}=\frac{\partial ^{2}E}{\partial a_{i}^{2}}x_{j}^2\cdots\cdots\cdots\cdots(6)}$$
second derivatives은 역전파된다.
$$\mathbf{\frac{\partial ^{2}E}{\partial a_{i}^{2}}=f'(a_{i})^2\sum_{l}w_{li}^{2}\frac{\partial ^{2}E}{\partial a_{l}^{2}}-f''(a_{i})\frac{\partial E}{\partial x_{i}}\cdots\cdots\cdots\cdots(7)}$$
마지막 layer weighted sum에 대한 E의 second derivative를 지정하는 output layer의 boundary 조건도 필요하다.
output layer의 모든 unit에 대해 $$\mathbf{\frac{\partial ^{2}E}{\partial a_{i}^{2}}=2f'(a_{i})^2-2(d_{i}-x_{i})f''(a_{i})\cdots\cdots\cdots\cdots(8)}$$
diagonal Hessian을 계산하는 것은 기울기를 계산하는 것과 유사한 정도의 복잡도를 갖는다. 마지막 두 식의 우변의 두번째 항을 무시할 수 있는 경우도 있다 (f의 2차 도함수가 포함된 항). 이는 잘 알려진 Levenberg-Marquardt approximation에 해당하며, second derivative의 양수 추정치를 보장하는 흥미로운 특성을 가지고 있다.
2.2 THE RECIPE
OBD 과정은 다음과 같다.
- 합리적인 네트워크 아키텍처 선택
- 합리적인 솔루션을 얻을 때까지 네트워크 학습
- 각 파라미터에 대해 second derivatives $h_{kk}$계산
- 각 파라미터에 대한 saliency 계산: $s_{k}=h_{kk}v_{k}^{2} /2$
- saliency에 따라 파라미터를 정렬한 후 low- saliency를 갖는 일부 파라미터들을 삭제
- 2단계부터 다시 반복
파라미터를 삭제한다는 것은 해당 파라미터를 0으로 설정하고, 동결하는 것(학습을 통해 업데이트 하지 않는 것)을 의미한다. 단순히 0으로 설정하는 것 이외에도 low- saliency 파라미터의 값을 줄이거나, 0으로 설정하고 동결하지않고 다시 학습에 사용하는 등 여러 방법을 생각해 볼 수 있다.
2.3 EXPERIMENTS
본 논문에서는 mnist와 같은 손으로 쓴 숫자 데이터를 활용하여 실험을 수행하였다. 데이터는 약 9300개의 학습 데이터와 3350개의 test 데이터로 구성되어 있다. 초기 네트워크는 2578개의 free 파라미터로 제어되는 105개의 connection이 있다 (dropout처럼 connection.을 끊은건가??).
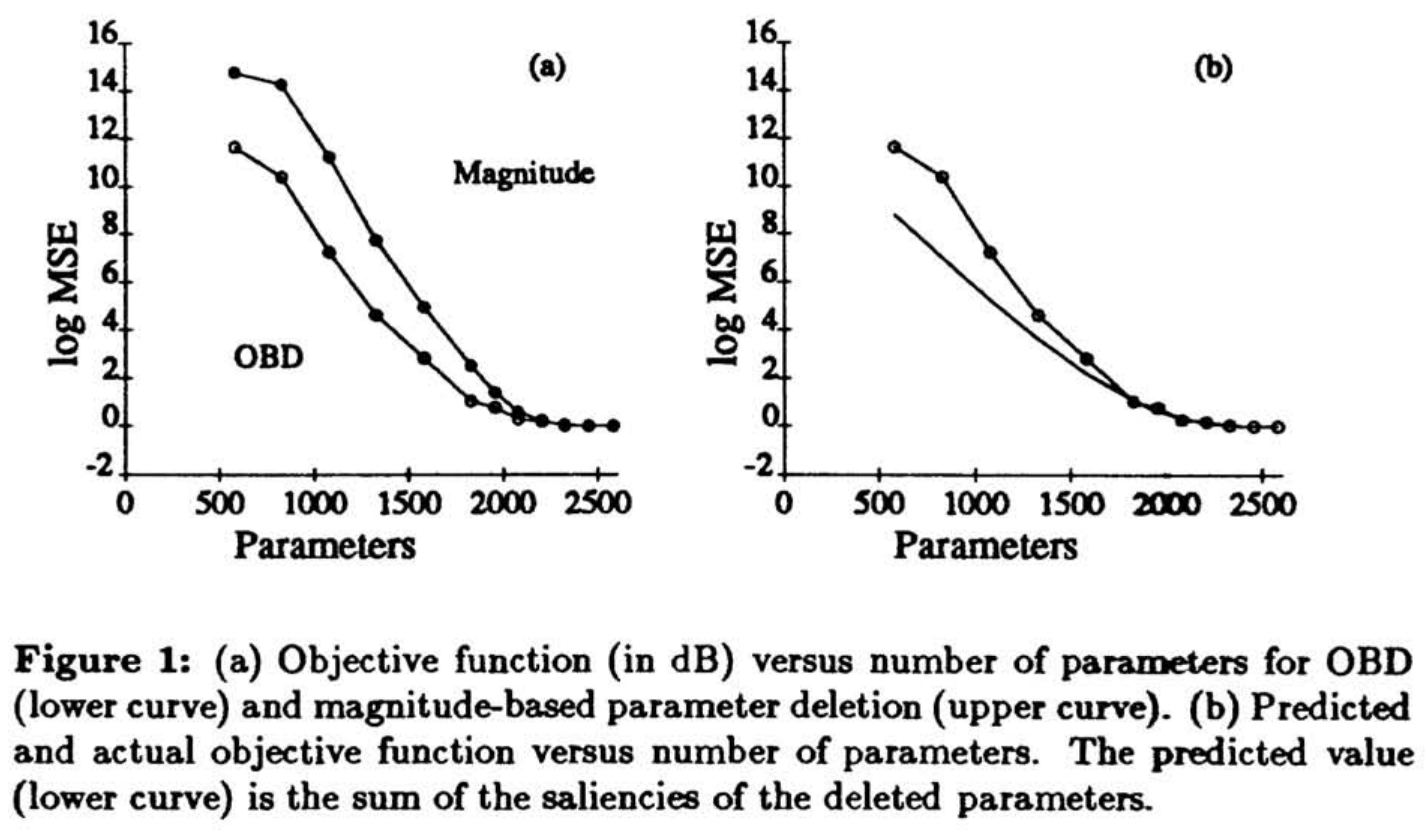
그림 1(a)는 파라미터의 수에 따른 objective function 변화를 보여준다. OBD 과정에 따라 saliency가 작은 파라미터부터 삭제하는 경우가 magnitude에 따라 삭제하는 경우보다 objective function 증가폭이 작다 (파라미터 랜덤 삭제하는 경우도 실험했으나, 성능이 매우 나빠 동일한 척도로 그래프에 표시할 수 없었다.).
그림 1(b)는 Quadratic-Extremum-Diagonal approximation에 의해 예측된 증가폭과 비교하여 파라미터의 수의 감소에 따른 objective function의 증가를 보여준다. 약 800개 (약 30%)가 삭제되었을 때 예측값과 일치하는 것을 확인할 수 있다. 이를 넘어서는 순간 예측값보다 더 높은 값을 보이는 데, 이는 다음과 같은 이유에 의한 것이다.
- 식 (1)의 off-diagonal(비대각)항은 삭제된 파라미터의 수가 증가할수록 불균형적으로 더 중요해진다.
- 큰 값의 파라미터가 삭제되면 higher-than-quadratic 항이 더 중요해진다.
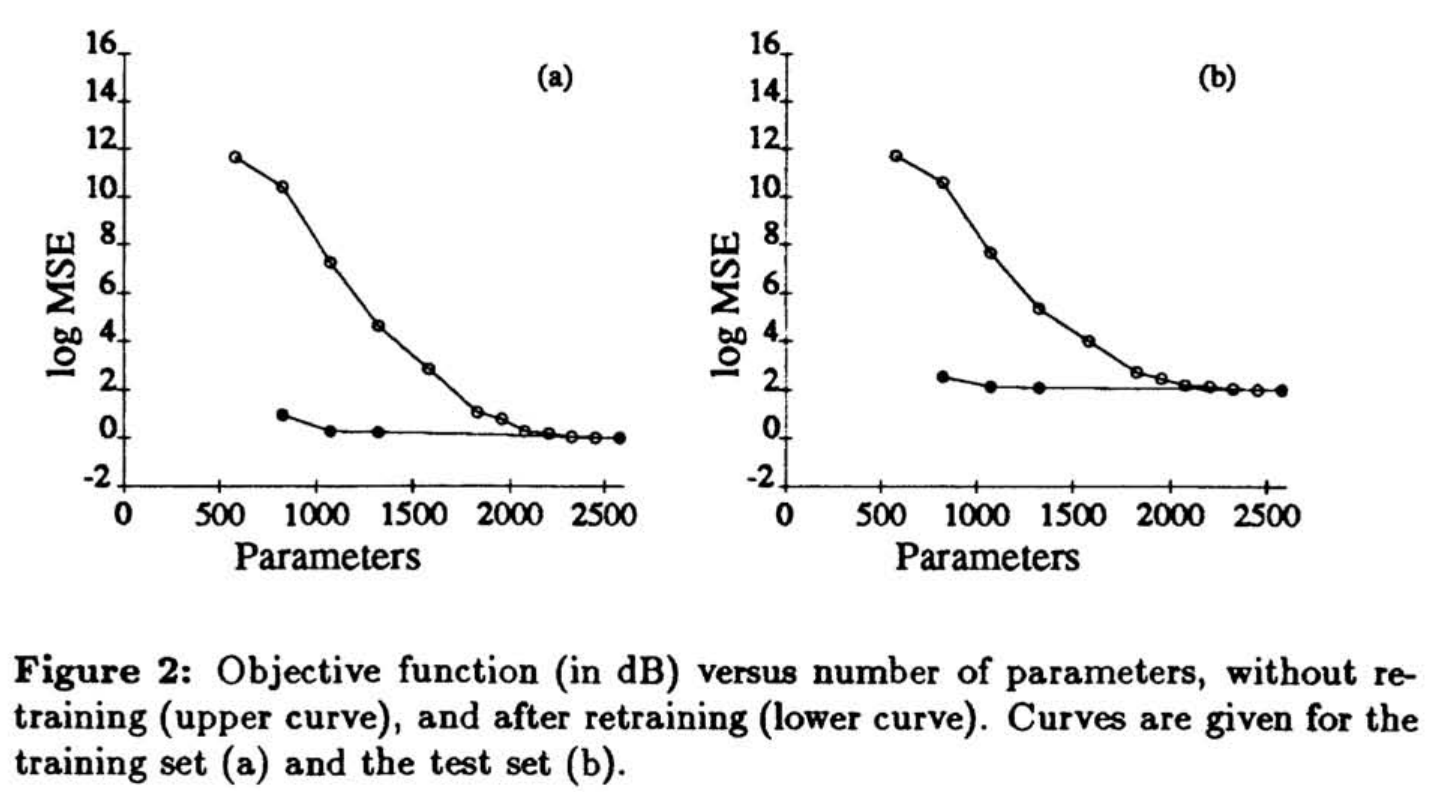
그림 2(a)는 재학습 후의 학습 데이터에 대한 objective function, 그림 2(b)는 테스트 데이터에 대한 object function을 보여준다. 최대 1500개 (60%)의 파라미터가 삭제되었을 때도 학습 및 테스트 데이터에 대한 성능은 삭제 전과 거의 동일하다.
우리는 OBD를 네트워크 설계 및 분석을 위한 interactive tool로 사용하였다 (아마 계속 변화하는 파라미터의 값을 고려하지 않고 일관적으로 삭제하는 방법이 아니라 학습 -> 가중치 제거 이 과정을 반복하며 최적의 파라미터 값+수를 찾기 때문에 interactive tool이라고 강조하는 듯 하다.). 이는 가중치 삭제를 자동적인 절차로 보는 관점과는 반대된다. 기존 digit recognition 네트워크에서 10000개의 파라미터의 saliency를 나타내는 차트에서 높은 saliency를 가지는 파라미터들을 제거할 수 있었다. 또한, 마지막에서 두번째 layer를 제거하여 파라미터의 수를 2배로 줄일 수 있었다. 이렇게 네트워크를 구성했을 때, 학습 데이터에 대한 MSE는 10배 증가하였지만, generalization MSE (이거는 테스트셋??)는 50%만 증가하였다. 테스트 셋에서의 classification error는 감소하였다 (이는 MSE가 해당 작업에 최적의 objective function이 아니라는 것을 의미한다.) (generalization MSE가 테스트셋을 의미한다면 말이된다. 테스트셋을 MSE로 측정하면 증가하였지만, classification error는 감소함. 근데, 이거만 가지고는 MSE가 최적이 아니라고 말하기 어렵지 않나?).
3 CONCLUSIONS AND OUTLOOK
본 논문에서는 OBD를 통해 실제 신경망에서의 파라미터 수를 4배로 줄였다. 이를 통해 네트워크의 많은? 속도 향상과 약간의 인식 정확도 향상이라는 결과를 얻었다. 이는 SOTA 모델과의 비교 결과인 것으로 매우 가치가 높다 (정확도 1%에서 11%되는 것과 95%에서 99%는 매우 다른 의미를 갖음).
우리가 제안한 방법들은 second-derivative information가 사용되는 네트워크에서의 시작일 뿐, 더 많은 방법들이 존재할 수 있다. 우리는 second-derivative information을 사용함으로써 "complexity equals number of free parameters"는 근사치?를 능가할 수 있었다 (). 우리는 이를 사용하여 네트워크의 information 혹은 복잡성에 대한 향상된 결과를 도출한다. 이를 통해 네트워크 아키텍처를 비교할 수 있고, MDL(Minimum Description Length)의 개념과 연관시킬 수 있다. 본 논문의 주요 아이디어는 "simple" 네트워크가 "complex" 네트워크보다 올바르게 일반화될 가능성이 높다는 것이다. 이는 아마도 일부 파라미터를 제거함으로써 데이터로부터 주요한 특징을 추출하고, 중복되는 정보들을 제거했기 때문이라 생각한다.
나오기 전에...
오랜만에 논문 정독한 것 같다. 짧은 논문인데도 불구하고 내가 바보가 됐나 싶을 정도로 걸리는 부분이 많았고, 특히 수식부분이 이해하기 어려웠다. 물론 지금도 완벽하게 이해하진 못했다. 다시 읽어봐야 할듯하다.
반응형'최적화' 카테고리의 다른 글
[최적화] Ensemble Knowledge Guided Sub-network Search and Fine-tuning for Filter Pruning 논문 리뷰 (작성중) (0) 2023.10.30 [최적화] Learning both Weights and Connections for Efficient Neural Networks 논문 리뷰 (작성중) (0) 2023.10.22 [최적화] Model Compression 논문 리스트 (0) 2023.10.17 [최적화] pytorch CSR 구현 (작성중) (0) 2023.10.12 [최적화] 딥러닝 모델 더 작게 만들기(경량화) 내용 정리 (1) 2023.09.05