-
[NLP] Transformer 정리Paper review/NLP 2021. 12. 6. 15:35반응형
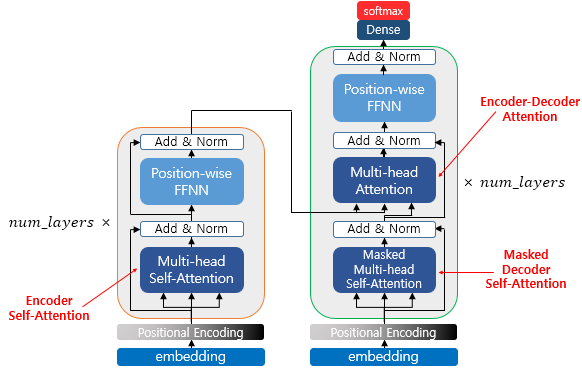
Transformer 구조
우선 Transformer의 구조는 다음과 같다.
Transformer과 동일한 차원으로 예제를 수행한다. "I am a student" 라는 문장을 독일어로 번역하는 예제이다.
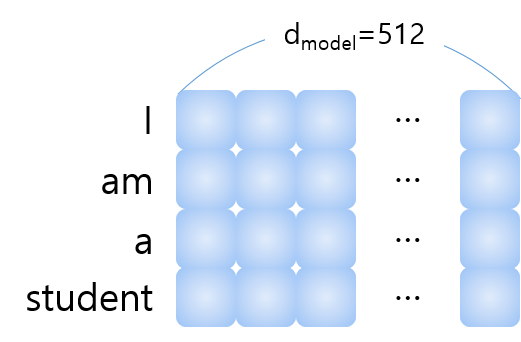
입력 문장은 다음과 같이 (입력 sequence) x 512 입력으로 들어온다. 이때, transformer는 병렬처리를 수행하기 때문에 문장의 순서 정보를 따로 추가해 주어야 한다. 이를 위해 input embedding에 positional encoding을 추가해준다.
Positional encoding
Positional encoding을 다양한 방법으로 설정해 보았다.
- 0~1사이의 라벨 사용: 아래 예시와 같이 문장의 총 길이에 따라 delta가 달라지게 된다 (delta=단어 label 간 차이=거리 차이)

- 1부터 순차적으로 사용: delta는 동일하지만, input이 아주 큰 경우, 일반화의 어려움이 존재한다 (라벨이 특정 범위가 아니기 때문)

Position은 유일한 값을 가져야 하고, 다른 길이의 input에서도 delta가 동일해야하며, 매번 다른 값이 나오면 안되고 (동일한 길이의 문장에서는 위치 정보도 동일), 일반화가 가능해야한다 (특정 범위 이내여야 함).
Transformer에서의 positional encoding 수식은 다음과 같다.
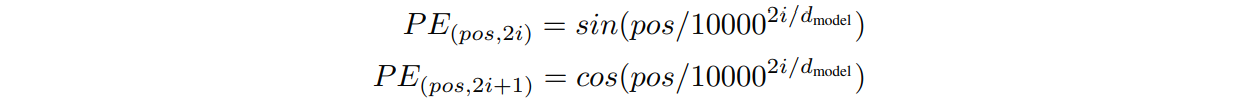
이때, pos는 입력 문장에서의 embedding 벡터의 위치를 나타내며, i는 embedding 벡터 내의 차원의 인덱스를 의미한다 (아래 그림에서는 pos=2, i=3). i가 짝수일때는 sin파, 홀수일때는 cos파를 사용한다.

positional encoding을 시각화 한 결과는 아래 그림과 같다. 아래 그림은 50개의 단어로 이루어진 문장에 대해 128차원 embedding으로 했을 때의 positional encoding이다.
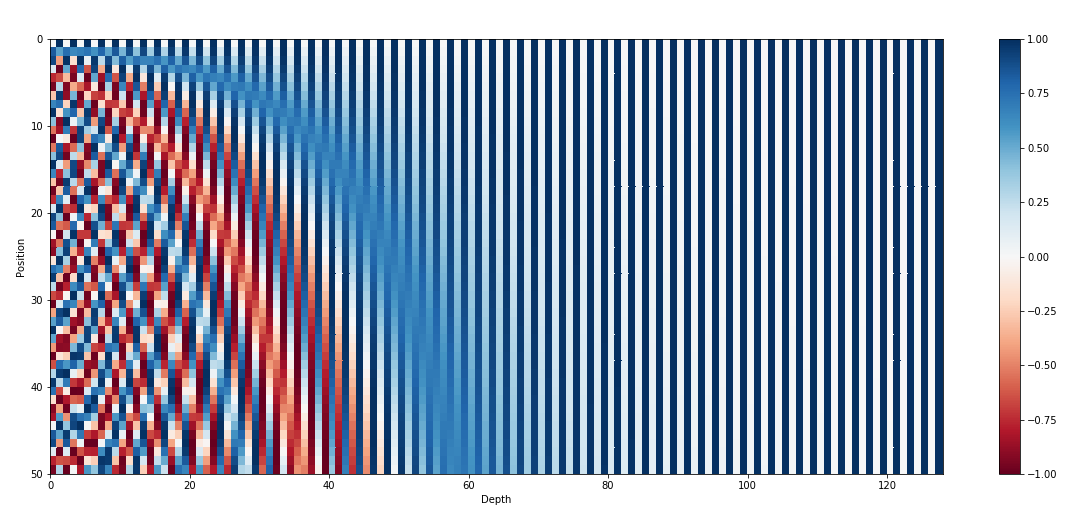
간단히 생각하면 각 차원별로 sin 혹은 cos 파의 값이다. 첫번째 각 단어들의 0차원을 보면, 첫번째 단어에서 값이 0이고, 두번째 단어에서 약 0.75, 이렇게, -1~1을 반복하는 값을 얻는 것을 확인할 수 있다. 즉 첫번째, 차원은 주기가 2π인 (2i=0) cos파를 따른다. 두번째 1차원을 보면 동일한 방법으로, 첫번째 단어에서 값이 1이고, -1~1을 반복하는 값을 얻는 것을 확인할 수 있다. 즉, 두번째 차원은 주기가 2π인 (2i=0) sin파를 따른다.
점점 차원이 증가함에 따라 i의 값이 증가하여 점점 주기가 커지는 sin, cos 파를 얻게 된다. 따라서 최대 주기는 10000*2π로 해당 길이의 문장까지 모두 다른 positional encoding을 생성할 수 있는 것이다.

Q, K, V 생성
Positional encoding이 포함된 input vector에 가중치를 곱하여 query, key, value를 생성한다.

이때 생성하는 Q: query는 영향을 받는 벡터, K: key는 영향을 주는 벡터, V: value는 영향을 주는 정도에 대한 가중치 벡터 이다. Q, K, V의 차원을 64로 한 이유는 병렬 처리를 위한 multi head가512/64=8이기 때문이다.
Attention 연산 수행
생성된 Q, K, V에 대해 attention을 수행한다.
Transformer는 scaled dot-product attention을 사용한다. 식은 다음과 같다.
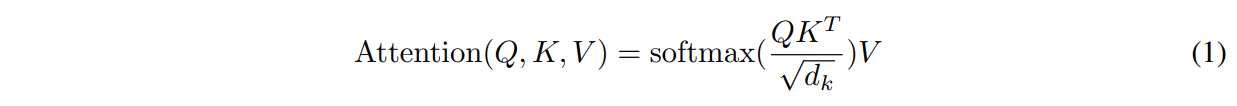
먼저 QK^T를 수행한다.
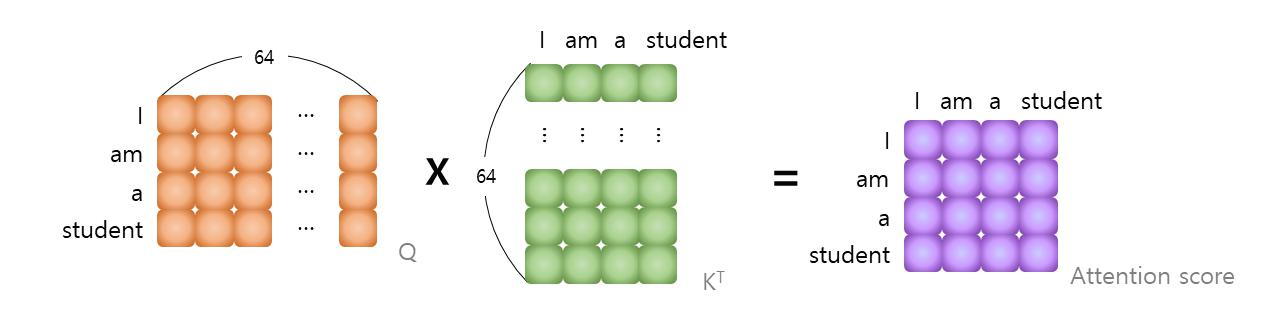
Attention score는 Q에 대해 K의 영향을 미치는 정도를 나타낸다.
이렇게 생성된 Attention score에 대해 √(d_k)하여 softmax를 적용한다. 이 연산을 수행한 후의 벡터를 attention distribution이라 하고, 차원은 유지된다.
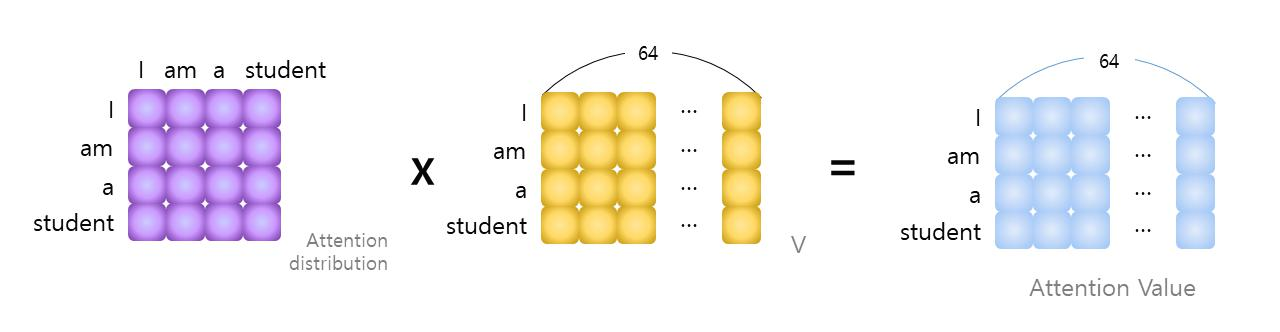
Attention distribution에 대해 V를 곱하여 최종 Attention value를 얻는다. 이러한 Attention value는 앞서 언급했듯이 8개의 multi head로 수행된다. 따라서 다음과 같이 attention value를 합친다.

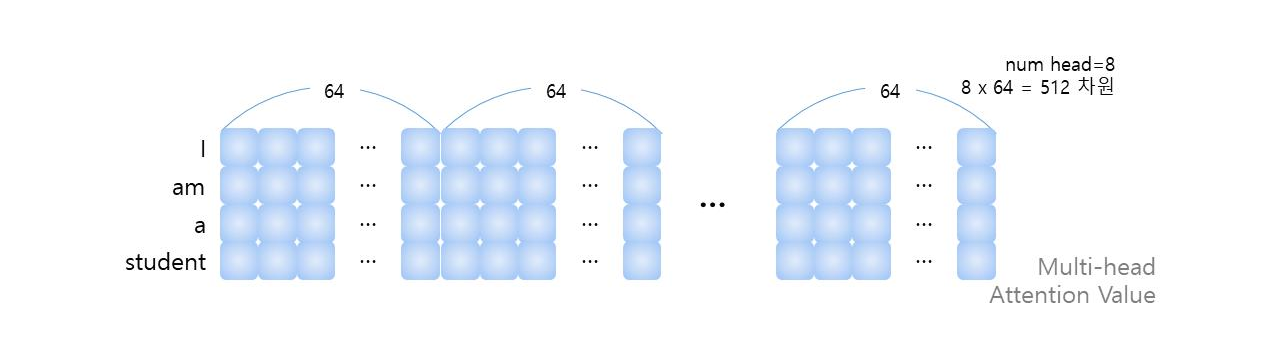
concat된 multi-head attention value에 대해 가중치 W^O를 곱하여 multi-head attention layer의 최종 output을 생성한다. 이 output은 input size와 동일한 (입력 sequence) x 512 차원이 된다.
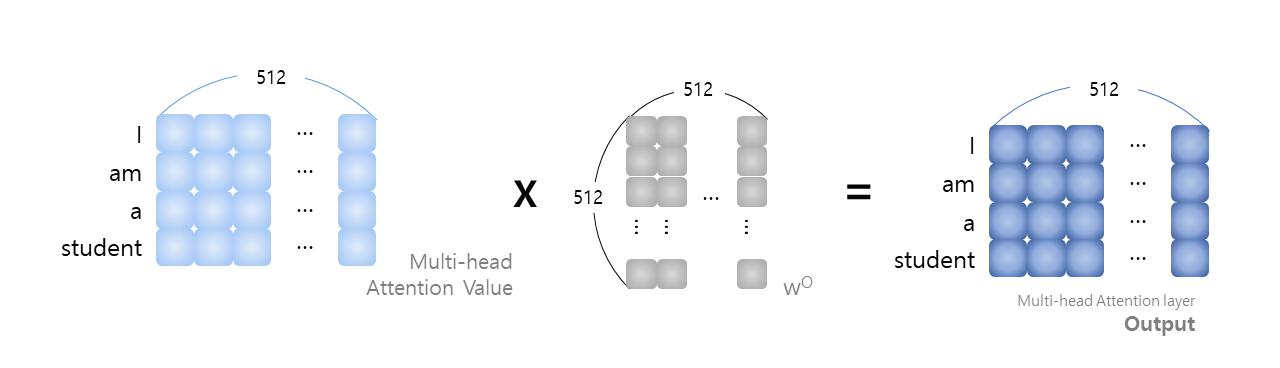
Output은 input과 더하여 정규화를 수행한다. 그 후 FFN, residual, 정규화를 수행한다.
Attention layer 종류
Transformer는 세 가지 방식으로 multi-head attnetion을 사용한다.
- "Encoder-Decoder Attention layer" 에서 query는 이전 decoder layer에서 얻고, key와 value는 encoder의 output에서 얻는다. 이를 통해 decoder의 모든 position이 input sequence의 모든 position에 배치될 수 있다. 이는 sequence-to-sequence 모델에서 일반적인 encoder-decoder attention 메커니즘과 동일하다.
- "Encoder Self-Attention layer" 는 encoder에 존재하며 query, key, value가 동일하며, 이는 encoder에 있는 이전 layer의 output이다. Encoder의 각 position은 이전 layer의 모든 position에 attend 할 수 있다.
- "Masked Decoder Self-Attention layer"는 decoder에 존재하며, 마찬가지로, decoder의 self-attention layer는 각 position이 해당 position의 위치까지 docoder의 모든 position에 attned하도록 한다. auto-regressive propert를 유지하기 위해 decoder에서 leftward information flow을 막아야 한다 (미래 시점의 단어를 볼 수 없도록 하는 것). 이를 위해 매우 작은 수를 부여하여 softmax 결과 0에 수렴하도록 하여 masking을 수행한다.우리는 잘못된 연결에 해당하는 소프트맥스 입력의 모든 값을 마스킹(-)로 설정)하여 스케일링된 도트 제품 주의의 내부에서 이를 구현한다.
쉽게 설명하면, seq2seq와 동일하게 생각할 수 있다. Encoder Self-attention은 영어 "I am a student"에 대한 context 벡터 생성 layer, Masked Decoder self-attention은 독일어 "je suis étudiant"에 대한 context 벡터 생성 layer, Encoder-Decoder attention은 영어와 독일어 context 벡터의 매칭 layer라고 생각하면 쉽다.Positional encoding에 대한 설명을 추가할 예정..
반응형'Paper review > NLP' 카테고리의 다른 글
[NLP] Attention Is All You Need 번역 및 정리 (Transformer) (0) 2021.12.06 - 0~1사이의 라벨 사용: 아래 예시와 같이 문장의 총 길이에 따라 delta가 달라지게 된다 (delta=단어 label 간 차이=거리 차이)