-
[Image-to-Image] TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up 번역 및 정리 (TransGAN)Paper review/Image-to-Image 2021. 12. 13. 11:46반응형
@ 굵은 글씨는 중요한 내용, 빨간 글씨는 내가 추가한 내용
https://arxiv.org/pdf/2102.07074.pdf
주요 기여
- Transformer + GAN -> TransGAN 제안
0. Abstract
최근 Transformer는 NLP뿐만 아니라 CV에서도 사용될 뿐만 아니라 classification, detection, segmentation과 같은 여러 task에서 SOTA를 달성하고 있다. 우리는 이를 generative adversarial networks (GANs)과 같은 어려운 vision task에 적용해본다. 우리의 목표는 Transformer 기반 아키텍처만을 사용하여 GAN을 구축하는 것이다. TransGAN이라고 불리는 우리의 표준 GAN 아키텍처는 feature resolution을 점진적으로 높이는 메모리 친화적인 transformer 기반 generator와 multi-scale discriminator로 구성되어 semantic context (global feature)와 low-level texture (local feature)를 동시에 포착한다. 또한 TransGAN을 고해상도 생성으로 확장하기 위해 메모리 병목 현상을 완화하기 위한 새로운 grid self-attention 모듈을 도입한다. 또한 data augmentation, modified normalization, relative position encoding과 같은 기술을 통해 TransGAN의 학습 불안정 문제를 완화한다. 우리는 CNN을 backbone으로 사용하는 현재 SOTA GAN에 비해 매우 경쟁력 있는 성능을 달성한다. 또한 training dynamics을 시각화하여 transformer 기반 generator 모델이 cnn 모델과 어떻게 다른지 이해하기 위해 transformer 기반 generator 모델을 조사한다. 코드는 https://github.com/VITA-Group/TransGAN 에서 확인할 수 있다.

1. Introduction
Generative adversarial networks (GANs)은 많은 task에서 높은 성능을 달성했다. 하지만 GAN의 학습 불안정성을 해결하기위해 normalization, loss, train setting과 같은 방법들을 적용해왔다. GAN을 개선하기 위해 많은 연구를 수행했는데, (generator) 백본 역할이 중요하다는 것을 관찰한다.
그러나, 하나의 "commonsense (상식)"는 거의 연구되지 않았다.: 무조건 CNN을 GAN 백본으로 사용해야 하는 것이다. 원래 GAN에서는 FC layer만을 사용했으며, small image만 생성할 수 있었다. DCGAN은 CNN 아키텍처를 사용하여 GAN을 최초로 scale-up한 것으로, 이는 고해상도 및 심층 생성 모델을 위한 안정적인 학습을 가능하게 했다. 그 이후로 CV 영역에서 모든 성공적인 GAN은 CNN 기반 generator와 discriminator에 의존한다.
Can we build a strong GAN completely free of convolutions? 기본적으로 CNN은 local receptive field를 가지므로, 충분한 수의 layer를 통과하지 않으면 long-range dependency를 처리할 수 없다. 그러나 이는 비효율적이며, 최적화의 어려움뿐만 아니라 특징 해상도와 세부 정보가 손실될 수 있다. 따라서 표준 CNN 기반 모델은 CV에 self-attention 및 non-local 연산을 채택했을 때의 이점으로 입증되었듯이 본질적으로 입력 이미지의 "global" 특징을 포착하는 데 적합하지 않다. 또한, convolution이 보유한 spatial invariance은 공간적으로 변화하는/이질적인 시각적 패턴에 적응하는 능력에 병목 현상을 일으키며, 이는 relational network, dynamic filters, kernel prediction 방법의 성공에 동기를 부여한다.
1.1 Our Contributions
본 논문은 CV 분야에서의 transformer의 성공을 기반으로 기존 Transformer 아키텍처만을 사용하여 CNN없이 GAN을 구축하는 것을 목표로 한다. 이미지 patch의 sequence에 직접 적용되는 표준 transformer 아키텍처가가 이미지 분류 작업에서 매우 잘 수행될 수 있지만, 동일한 방법이 이미지 생성에 효과적인지 여부는 불분명하며, 이는 구조, 색상 및 텍스처의 공간적 일관성과 디테일의 풍부함을 결정적으로 요구한다. 세세한 부분 이미지를 출력(generate)하는 소수의 기존 transformer는 모두 CNN을 활용하였다. 또한 잘 설계된 CNN 기반 아키텍처에서도 GAN 훈련은 불안정하며 mode collapse가 발생하기 쉽다. Vision transformer를 학습시킬 때, 매우 오래 걸리고 무겁고 데이터가 많이 필요한 것으로 알려져 있다. 두 가지를 결합하면 훈련의 어려움이 증폭될 것이다.
이러한 과제를 고려하여, 본 논문은 TransGAN이라고 하는 표준 transformer 기반 GAN 아키텍처를 구축한다. 우리는 각 단계에서 feature map 해상도를 점진적으로 높여 메모리 절약 transformer 기반 generator를 만든다. 이에 따라 다양한 크기의 patch를 입력으로 가져가는 multi-scale 구조로 discriminator로 개선하며, 메모리 효율성을 더욱 향상시킬 뿐만 아니라 global context와 local context 간의 균형을 맞춘다. 위의 G-D 설계에 기초하여, 우리는 TransGAN을 고해상도 생성(EX:256 × 256)으로 확장할 때 메모리 병목 현상을 더욱 완화하는 grid self-attention 모듈을 도입한다.
GAN과 Transformer 모두에 의해 야기된 불안정 문제를 해결하기 위해, 우리는 또한 우리의 혁신적인 TransGAN 아키텍처와 관련하여 최적화와 일반화를 효과적으로 안정화시키는 고유한 학습 방법을 제안한다. 여기에는 data augmentation, modifying layer normalization, replacing absolute token locations with relative position encoding의 필요성이 요약되어 있다.- Novel Architecture Design: Cnn 없이 기존 transformer를 사용하여 GAN을 구축한다. TransGAN은 메모리 친화적인 generator와 multi-scale discriminator를 정의하고, self-grid attention 메커니즘을 추가한다. 이러한 아키텍처 구성 요소는 메모리 효율성, global & local feature과 spatial variances의 균형을 맞추도록 설계된다.
- New Training Recipe: 우리는 generator와 discriminator 모두에 대해 data augmentation, modifying layer normalization, replacing absolute token locations with relative position encoding을 포함하여 TransGAN을 더 잘 훈련시키기 위한 여러 기술을 연구한다.
- Performance and Scalability: TransGAN은 현재 SOTA GAN에 비해 매우 경쟁력 있는 성능을 달성한다.
2. Related Works
Grid selGenerative Adversarial Networks.
Transformers in Computer Vision.
Transformer Modules for Image Generation.
3. Technical Approach: A Journey Towards GAN with Pure Transformers
Grid self-attention이 존재하는 memory 친화적 generator와 multi-scale discriminator를 설명한 후, data augmentation, 수정 normalization, 학습 기술에 대해 설명한다.
Transformer encoder를 기본 block으로 선택하고 최소한의 변경만 수행한다. Encoder는 두 개의 sublayer (multi-head self-attention과 GELU 비선형성을 가진 feed-forward MLP)로 이루어져 있다. Normalization layer는 sublayer보다 먼저 이루어 지고, residual connection이 존재한다. (이 부분은 Transformer를 읽고 봐야 이해가 쉽다.)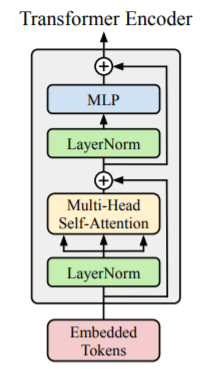
3.1 Memory-friendly Generator
Generation task는 구조, 색상 및 질감의 공간적 일관성에 대해 global, local 적으로 높은 기준을 제시한다. Transformer encoder는 embedded token word를 input (seq_length x d_model(512) = 512차원으로 임베딩된 단어가 n(=seq_length)개 존재하는 문장)으로 받아 각 token간의 상호작용을 계산한다. The main dilemma here is: what is the right “word" for image generation tasks? 비슷하게 transformer encoder stacking을 통해 픽셀 단위로 이미지를 생성하면 저해상도 이미지(EX. 32 × 32)에 대해서도 지나치게 긴 시퀀스(EX. 1024)가 생성되어 self-attention의 폭발적 cost가 발생하고 더 높은 해상도로 확장성이 금지될 수 있다. 이러한 많은 비용을 피하기 위해 CNN 기반 GAN의 joint 설계를 기반으로 여러 단계에서 해상도를 반복적으로 upscaling한다. 따라서 우리는 input sequence를 증가시키고 embedding 차원을 점진적으로 줄인다.
아래 그림은 여러 단계로 구성된 Generator의 아키텍처이다. 각 단계에는 여러 transformer block을 쌓는다. 최종 해상도 H x W가 되도록 단계마다 feature map 해상도를 점진적으로 증가시킨다. 특히 generator는 random noise를 input으로 받아 multi-layer perceptron(MLP)를 통해 (H0 × W0) × C 길이의 벡터로 전달한다 (기본적으로 H0 = W0 = 8 사용). 벡터는 H0 × W0 해상도 feature map으로 reshaped되며, 각 점은 C차원 embedding이다. 이 "feature map"은 학습 가능한 positional encoding과 결합된 C차원 token의 길이가 64인 시퀀스로 처리된다.
더보기GAN 학습과정 시각화

Random noise 
학습 과정 시각화 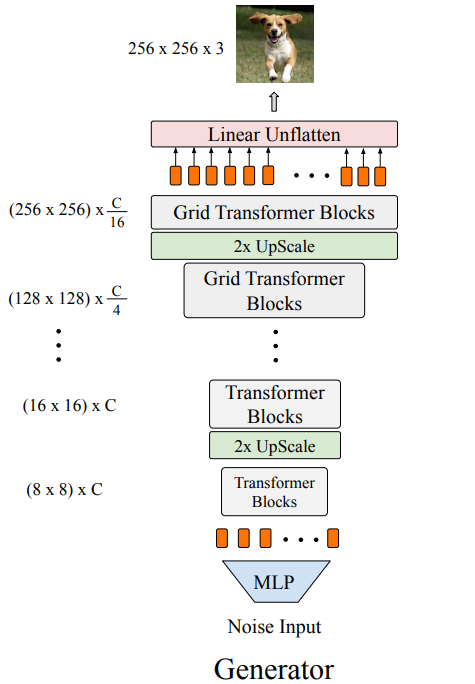
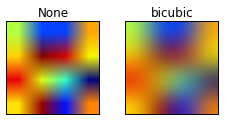
고해상도 이미지로 확장하기 위해 각 단계 후에 reshape 및 해상도 upscaling layer로 구성된 upsamling module을 삽입한다. 낮은 해상도 단계 (64 x 64보다 낮은 해상도)에서 upsampling module은 먼저 1D sequence of token을 2D feature map Xi ∈ R^(Hi×Wi×C)으로 reshape한다. Embedded dimension이 변경되지 않는 동안 bicubic layer를 채택하여 그것의 해상도를 upsample하여 output X'i ∈ R^(2Hi×2Wi×C)를 생성한다.
더보기Bicubic upsampling
이미지를 upscaling할 때, 각 픽셀의 값을 인접한 16개의 화소의 화소값과 거리에 따른 가중치의 곱을 사용하여 결정한다.
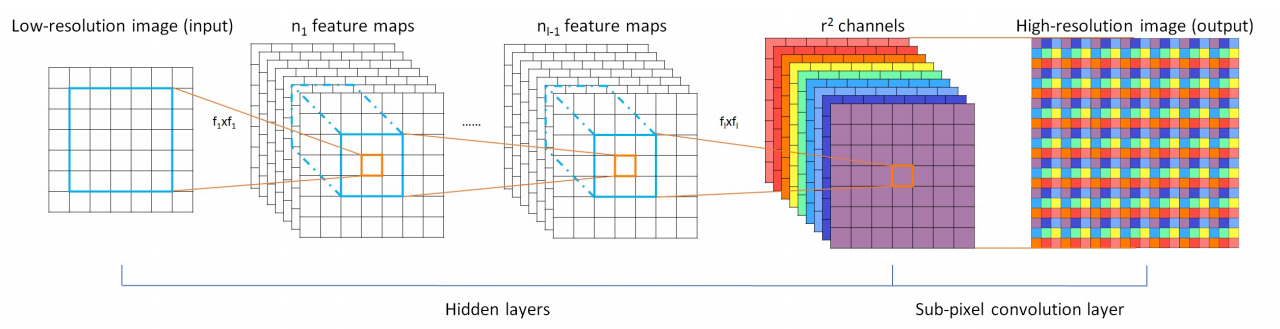
그 후, 2D feature map X'i는 token embedded 1D 시퀀스로 다시 reshape된다. 고해상도 단계의 경우, bicubic upscaling layer를 pixelshuffle module로 교체하여 feature map의 해상도를 2배 비율로 높이고 embedded dimension도 input의 1/4로 줄인다.
더보기Pixelshuffle upsampling
R배로 upscaling을 하고자 하는 경우, Convolutional layer를 거친 뒤 마지막 layer에서 feature map의 개수를 r 제곱개로 만들어 준 뒤, 각 feature map의 값들을 위의 그림처럼 순서대로 배치하여 1 채널의 HR 이미지로 만들어 준다.
(H,W 각각 r배가 되면 채널은 1/r*r로 줄어든다)
asdf
수정된 upscaling layer가 있는 이 피라미드 구조는 메모리와 계산 explosion을 완화한다. 목표 해상도(H, W)에 도달할 때까지 여러 단계를 반복한 다음 embedding 차원을 3으로 projection하여 RGB 이미지 Y ∈ R^(H×W×3)를 구한다.
3.2 Multi-scale Discriminator
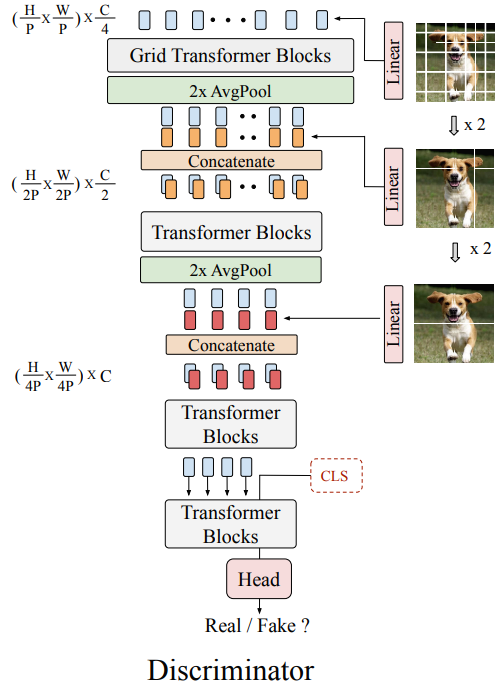
정확한 픽셀까지 합성을 수행하는 generator와 달리 discriminator는 real image와 fake image를 구별하는 task을 수행한다. 따라서 이미지의 patch를 "word"로 간주하여 즉, patch-level에서 input image를 token화 하는 것이 가능하다. Real과 fake를 구별해야되기 때문에 patch 분할 규칙이 중요한 역할을 하며, 큰 patch 크기는 낮은 수준의 텍스처 세부 정보를 잃어버리고, 작은 patch 크기는 더 많은 메모리를 소모하는 긴 시퀀스를 초래한다. 위의 딜레마는 다음 나오는 multi-scale discriminator의 설계에 동기를 부여한다.
아래 그림에서 볼 수 있듯이, multi-scale discriminator는 다양한 stage에서 다양한 크기의 patch를 input으로 받아들인다. 먼저 Y ∈ R^(H×W×3) image를 세 개의 다른 sequence로 분할한다 (patch sizes (P, 2P, 4P)). 가장 긴 sequence (H/P × W/P) × 3는 (H/P × W/P) × C/4로 선형 변환된 후 학습 가능한 position encoding과 결합되어 첫 번째 input으로 사용된다 (C/4는 embedded dimnesion size). 동일하게, 두 번째, 세번째 sequence도 각각 (H/2P × W/2P) × C/4와 (H/4P × W/4P) × C/2로 선형 변환된 후 2, 3 단계로 concatenated된다. 따라서 이 세가지 다른 sequence는 semantic structure와 texture details 모두를 추출할 수 있다. Generator와 유사하게, 1D-sentence를 2D feature map으로 reshape하고 Average Pooling layer를 통해 feature map 해상도를 줄인다. 이와같이 multi-scale 표현이추출되는 피라미드 아키텍처를 설계한다. 각 block의 끝에서 [cls] token이 sequence의 시작 부분에 추가된 다음, CLS head가 real/fake 예측을 출력한다.
3.3 Grid Self-Attention: A Scalable Variant of Self-Attention for Image Generation
self-attention을 통해 G는 global correspondence를 포착할 수 있지만, 긴 sequence/높은 해상도를 모델링할 때, 효율성이 낮아질 수 있다. 이는 text와 vision모두에서 해결되어야 한다. 따라서 우리는 grid self-attention 방법을 제안한다.
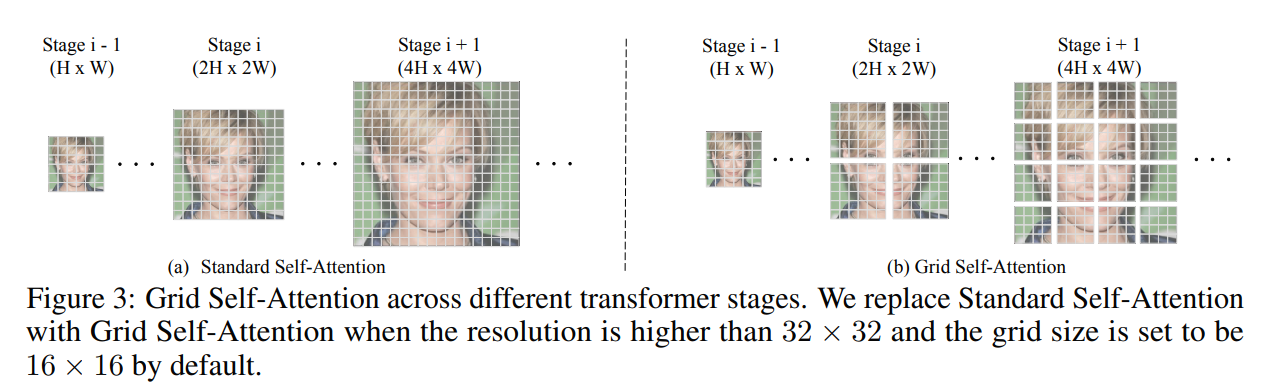
위의 그림에서 볼 수 있듯이, 주어진 token과 다른 모든 token사이의 관계를 계산하는 대신, grid self-attention은 feature map을 겹치지 않은 여러 grid로 분할하고 token과의 관계를 각 local grid 내부에서만 계산한다. 고해상도(32 x 32 이상) 단계에서는 grid self-attention을 수행하고, 저해상도 단계에서는 표준 self-attention을 수행하여 이미지의 local, global 특징을 모두 얻는다 (고해상도 일때, local 특징을 얻고, 저해상도 일때, global 특징을 얻음). 이는 generation task에서 좋은 성능을 보인다.
각 그리드 사이의 인위적인 경계과와 관련하여 한 가지 잠재적 문제가 발생할 수 있다. 하지만 이는 충분한 학습이 수행되면 점차 사라지며 명시적인 그리드 중첩이 없어도 좋은 최종 결과를 산출한다는 것을 관찰한다. 우리는 이것이 서로 다른 스케일로 생성된 이미지 fidelity를 요구하는 discriminator의 더 큰 다중 스케일 수용 필드 때문이라고 생각한다.
3.4 Exploring the Training Recipe
Data Augmentation.
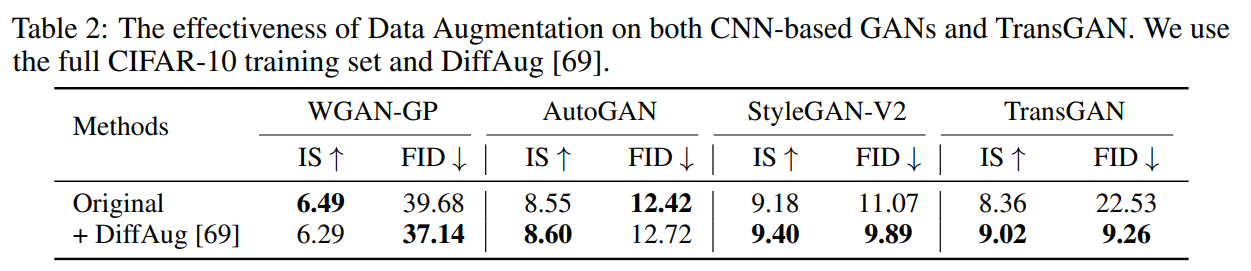
{T ranslation, Cutout, Color} data augmentation 수행 시 CNN기반 GAN에 비해 transformer 기반 GAN에 훨씬 많은 성능 향상을 보임
Relative Position Encoding.
Modified Normalization.
4. Experiments
Datasets
Implementation
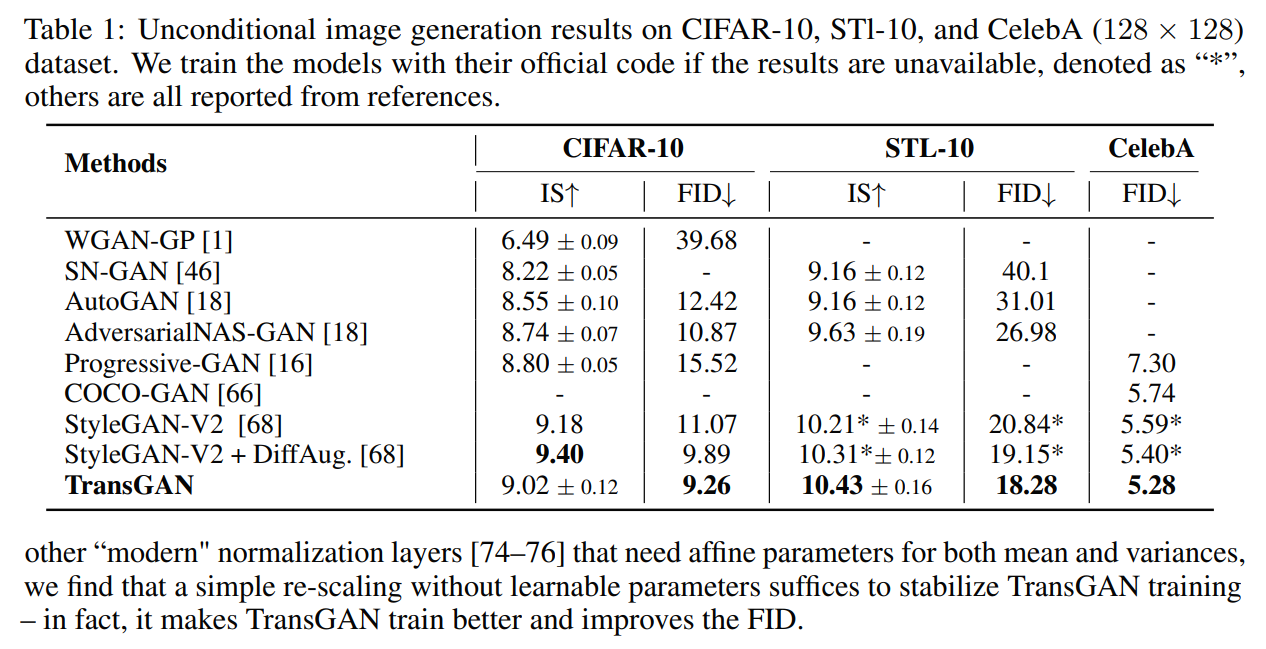
4.1 Comparison with State-of-the-art GANs
4.2 Scaling Up to Higher-Resolution

4.3 Data Augmentation is Crucial for TransGAN
4.4 Ablation Study
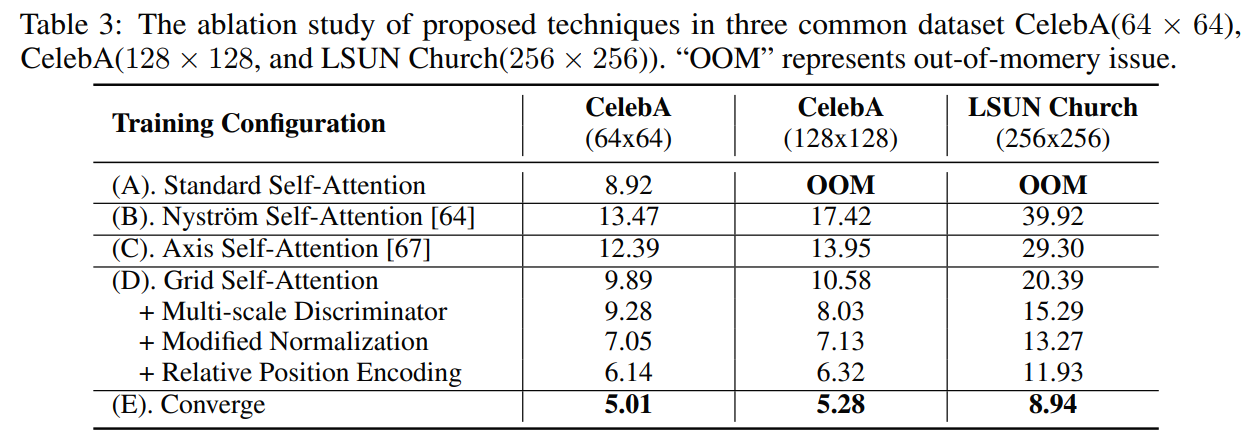
4.5 Understanding Transformer-based Generative Model

5. Conclusions, Limitation, and Discussions of Broad Impact
본 연구에서는 표준 transformer로 GAN을 구축하였다. 이를 통해 제안된 TransGAN은 많은 dataset에서 SOTA를 달성하며, 고해상도 생성 task로 쉽게 확장된다. 하지만 아직 미래 방향인 초고해상도 생성 작업(EX. 1024 × 1024)과 같이 아직 더 탐구할 여지가 많다.
Broader Impact.
제안된 generative 모델은 data 수집 문제를 해결하는 data engine 역할을 할 수 있고, 합성 image data를 사용하는 것이 privacy concern을 피하는 데 도움이 된다. Generative 모델을 더 많은 사람들이 접근할 수 있게 함으로써, TransGAN은 모든 사람들이 예술적인 창작물을 만들 수 있도록 돕는 편리한 방법을 제공하지만, generative 모델의 남용은 또한 더 많은 가짜 뉴스를 만들 수 있고, 이것은 앞으로 더 효과적으로 제한되어야 한다.반응형'Paper review > Image-to-Image' 카테고리의 다른 글