-
[Paper short review] TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation 번역 및 설명Paper short review 2022. 2. 10. 15:22반응형
@ 굵은 글씨는 중요한 내용, 빨간 글씨는 내가 추가한 내용
https://arxiv.org/pdf/2102.04306.pdf
- 정리: 의료 영상 segmentation + transformer
0. Abstract
- 기존 의료 영상 segmentation은 모두 U-Net을 기반으로 함
- But. CNN의 본질적인 특성으로 인해 global 특징을 모델링하는 데에 한계
- Sequence2Sequence를 위해 제안된 transformer는 self-attention을 통해 global 특징을 모델링하는 데에 탁월
- But. low level의 세부 정보가 충분하지 않아 localization 성능 저하
- transformer와 unet의 장점을 모두 활용하는 의료 영상 segmentation 모델인 TransUnet 제안
- transformer는 global context를 추출하기 위해 CNN feature map에서 token화 된 patch를 encoding
- decoder는 encoding된 특징을 증폭시켜 CNN feature map과 결합하여 보다 정확한 localization 수행
- TransUNet은 다양한 의료 application에서 기존 방법보다 우수한 성능 달성
- 코드 및 모델 https://github.com/Beckschen/TransUNet
1. Introduction
- 의료 영상 segmentation task
- CNN/FCN이 대부분 활용됨
- 특히, skip connection이 있는 encoder-decoder 구조 U-Net이 범용 아키텍처임
- CNN의 본질적인 특성은 장거리 관계를 모델링하는 데에 한계점이 존재함
- 이를 해결하기 위해, CNN feature를 기반으로 self-attention을 수행하는 방법이 제안되었다.
- CNN과 달리, transformer는 global context를 모델링하는 데에 강건함
- transformer는 NLP에서 크게 성공, 최근에는 CV task에 적용하여 경쟁력 있는 성능을 보임
- 의료 영상 segmentation에서 transformer를 활용
- But. standard trnasformer만 사용했을 때, 좋은 성능을 얻지 못함
- transformer는 input을 1D sequence로 처리하고, global context를 모델링하는 데에 효과적이기 때문에, local context 정보가 부족함
- 반면, CNN 기반 아키텍처는 local context 정보 모델링에 효과적
- TransUnet 제안
- transformer가 인코딩한 global context와 cnn의 local context를 모두 활용하기 위한 하이브리드 아키텍처 제안
2. Related Works
Combining CNNs with self-attention mechanisms
- self-attention을 CNN에 통합하려는 다양한 연구 수행
- Proceedings of the IEEE conference on computer vision and pattern recognition.
- Attention gated networks: Learning to leverage salient regions in medical images.
- global self-attention을 포함시키기 위해 transformer 활용
Transformers
- Transformer는 기계 번역을 위해 제안되었고, 많은 NLP task에서 SOTA 달성
- 최근transformer를 CV에서도 활용
- Image transformer. In: International Conference on Machine Learning.
- Generating long sequences with sparse transformers.
- An image is worth 16x16 words: Transformers for image recognition at scale.
- 최초의 transformer 기반 의료 영상 segmentation 프레임워크 제안
3. Method
- 목표: H × W 크기의 해당 픽셀 단위 lable map을 예측하는 것
- input: x ∈ R^(H×W×C)인 이미지 (해상도 = H × W, 채널 수 = C)
- 일반적인 메커니즘은 이미지를 feature로 encoding한 후 전체 해상도로 decoding하도록 학습하는 것임
- transformer의 self-attention을 encoder에 도입
3.1 Transformer as Encoder
Image Sequentialization
- Vision Transformer와 같이, input x를 2D 패치 {xp^i∈ R ^(P^2 ·C) |i = 1, .., N} sequence로 reshape (
- 패치 사이즈 = P×P
- N = HW/P^2 = 이미지 패치 수 = 입력 시퀀스 길이
Patch Embedding
- patch xp를 D차원 embedding 공간에 mapping
- 위치 정보 추가 (Epos)
- E ∈ R ^((P 2 ·C)×D) = patch embedding projection
- Epos ∈ R^(N×D) = position embedding

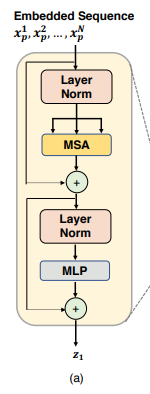
- Transformer encoder는 MSA(Multihead Self-Attention), MLP(Multi-Layer Perceptron) block의 L개의 레이어로 구성
- LN(·) = layer normalization
- zl =은 encoded image representation
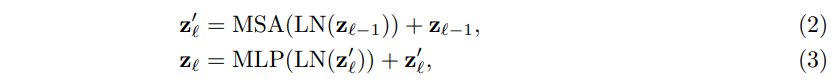
3.2 TransUNet

- segmentation을 위해, transformer에서 인코딩된 표현 zL ∈ R^(HW/P^2 ×D)을 최대 해상도로 업샘플링 수행
- 인코딩된 형상의 크기를 HW/P^2에서 H/P × W/P로 reshape (sequence -> image)
- cascaded upsampler 제안
- transformer와 기존 upsampling을 결합해도 좋은 성능을 얻을 수 있지만, H/P × W/P 는 원래 해상도 H × W보다 훨씬 작기 때문에 이는 최적의 방법이 아님
- 이러한 정보 손실을 보상하기 위해 Trans는UNet은 정확한 localization이 가능하도록 cascaded upsamler와 하이브리드 아키텍처 채택
CNN-Transformer Hybrid as Encoder.
- CNN을 통과한 feature map에 대해 transformer 수행
- 디코딩 시 skip connection을 통해 중간 고해상도 CNN feature map 활용 가능
- 하이브리드 아키텍처가 standard transformer 보다 높은 성능을 보임
Cascaded Upsampler.
- 여러 upsamling 단계로 구성된 cascaded upsampler (CUP) 제안
- zL ∈ R^(HW/P^2 ×D)을 zL ∈ R^(H/P × W/P ×D)로 reshape
- H/P × W/P에서 H × W까지 도달하기 위해 cascading multiple upsampling blocks
- 하이브리드 인코더와 함께 CUP가 U자형 아키텍처를 형성하여 스킵 연결을 통해 다양한 해상도 수준에서 feature 활용 가능
4. Experiments and Discussion
4.1 Dataset and Evaluation
- Synapse multi-organ segmentation dataset 사용
- 3779개의 영상
- Automated cardiac diagnosis challenge
4.2 Implementation Details
- data augmentation 적용 (random rotation, flipping)
- 모델
- Standard transformer 기반 Encoder: 12개의 transformer layer가 있는 ViT 채택
- Hybrid 설계: ResNet-50과 ViT의 결합 (=R50-ViT)
- ViT와 ResNet-50(=R-50)은 ImageNet에서 사전 학습
- 입력 해상도 = 224x224
- 패치 크기 P = 16
- SGD optimizer: learning rate =0.01, momentum=0.9, weight decay=1e-4, batch=24
4.3 Comparison with State-of-the-arts
- 기존 SOTA 모델 (V-Net, DARR, U-Net, AttnUNet)들과 TransUnet의 비교 실험 수행 (Synapse)
- CUP 디코더의 효과를 입증하기 위해 ViT를 인코더로 사용하고, standard 업샘플링과 CUP를 각각 디코더로 사용하여 비교 수행
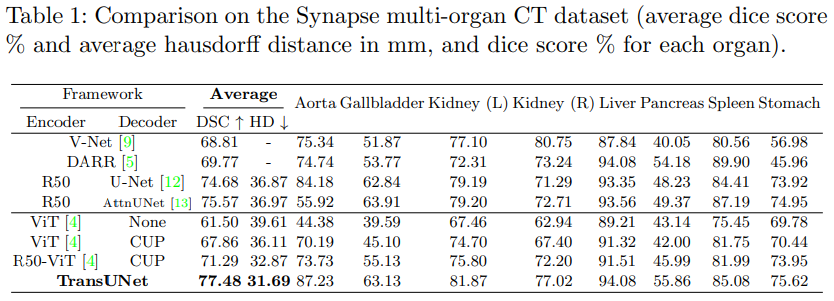
- R50-ViT-CUP를 기반으로 구축된 skip connection TransUnet이 최상의 결과를 보인다는 것을 확인할 수 있음
- 첫째, ViT-None과 비교하여 ViT-CUP는 평균 DSC와 HD 지표에서 각각 6.36%와 3.50mm 개선
- 이는 CUP가 기존 업샘플링보다 더 나은 디코딩 전략을 제시한다는 것을 입증
- 또한, ViT-CUP와 비교하여 R50-ViT-CUP는 DSC와 HD 지표에서 각각 3.43%, 3.24mm 추가 개선
- 하이브리드 인코더의 효과 입증
- 첫째, ViT-None과 비교하여 ViT-CUP는 평균 DSC와 HD 지표에서 각각 6.36%와 3.50mm 개선
- TranUnet은 기존 방법론에 비해 높은 개선률을 보임
- 트랜스포머가 의료 영상의 미세한 형태를 분할하기 위한 낮은 수준의 단서 정보 부족
- ViT-CPU의 경우 성능이 높아지지만, U-Net이나 AttnUNet보다는 낮음
- R50-ViT-CUP의 경우, V-Net와 DARR보다는 성능이 높지만 순수한 CNN 기반 R50-U-Net, R50-Atnunet보다는 낮은 결과를 보임
- Skip connection을 통해 U-Net 구조와 결합한 TransUNet이 SOTA를 달성
- 의료 영상 segmentation에 중요한 세부 정보(low level)뿐만 아니라 global 특징(high level) 모두를 학습
- 트랜스포머가 의료 영상의 미세한 형태를 분할하기 위한 낮은 수준의 단서 정보 부족
4.4 Analytical Study
- TransUner 평가를 위해 여러가지 설정에서의 실험 수행
- the number of skip-connections
- input resolution
- sequence length and patch size
- model scaling
The Number of Skip-connections
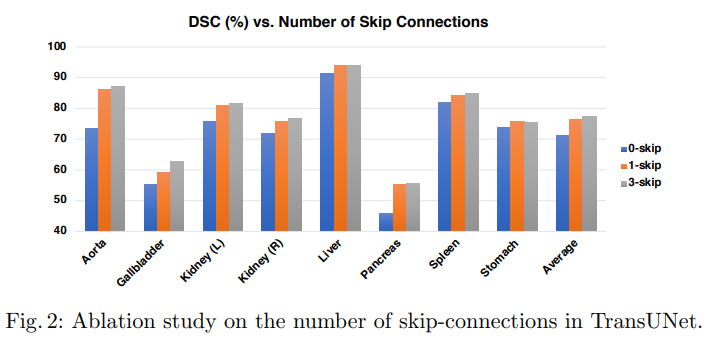
- skip connection 수에 따른 연구 수행
- skip connection을 통해 low level의 정보 활용 가능
- skip connection이 증가할 수록 성능이 향상된다는 것을 확인할 수 있음
- 논문에서는 3개의 skip-connection 채택
On the Influence of Input Resolution

- Image 해상도에 따른 연구 수행
- 기본 input size = 224×224
- input size를 512×512로 변경 시 동일한 patch size에서 transformer의 sequence 길이가 약 5배 길어짐
- 유효 sequence 길이가 늘면 성능이 향상되지만, 계산 비용이 매우 늘어나게 됨
- 논문에서는 계산 비용을 고려하여 224x224의 기본 해상도로 수행
On the Influence of Patch Size/Sequence Length.

- patch size에 따른 연구 수행
- patch size가 작을 수록 높은 segmentation 성능을 보이지만, 높은 종속성이 발생함 (계산량 많아짐)
- 논문에서는 기본 patch size 16 x 16 채택
Model Scaling

- TransUnet의 모델 크기에 따른 연구 수행
- Base, Large 모델 중 Large 모델이 더 좋은 성능을 보이지만, 논문에서는 계산 비용을 고려하여 base 모델 채택
4.5 Visualizations

- TransUner의 정성적 결과
- 기존 CNN기반 방법은 over-segmentation 발생
- 두 번째 행에서 확인 가능
- transformer를 활용함으로써 global 특징을 보존한다는 것을 입증
- 두 번째 행에서
- 첫 번째 행의 결과를 보면, TransUnet이 다른 모델에 비해 false positive가 적음
- 이러한 noise를 억제하는 데에 유리하다고 판단 가능
- Transformer-based 모델 비교 시 TransUnet이 R50-ViT-CUP보다 더 미세한 예측 수행 (EX. 두번째 행)
- 두 번째 행에서, TransUnet이 더 정교한 예측을 수행
- 세 번째 행에서, TransUNet은 왼쪽과 오른쪽 신장을 모두 정확하게 예측하지만, R50-ViT-CUP는 왼쪽 신장을 정확히 예측하지 못함
- 이는 TransUNet이 세부적인 특징 정보를 보존한다는 것을 증명
- TransUnet은 global, local 정보를 모두 보존하지만, R50-ViT-CUP는 global 정보에만 의존
- U-Net과 같은 스킵 연결을 transformer 설계에 통합함으로써 정확한 segmentation을 가능하게 함
- 기존 CNN기반 방법은 over-segmentation 발생
4.6 Generalization to Other Datasets
- TransUnet의 일반화 능력을 평가하기 위해 다른 dataset에 대해서 실험 수행
- 앞의 실험과 유사하게, 기존 방법론에 비해 개선된 성능을 보이는 것을 확인할 수 있음
5. Conclusion
- 의료 영상 segmentation을 위한 transformer 기반 모델 TransUnet제안
- transformer는 self-attnetion 메커니즘을 통해 global context를 보존
- cnn feature를 시퀀스로 처리한 후 transformer에 input하여 global context 활용
- u자형 아키텍처를 통해 local context 활용
- 기존 FCN 기반 접근법의 대안 프레임워크로서 우수한 성능 달성
My Discussion
Why this paper?
asdf
--> asdf
반응형'Paper short review' 카테고리의 다른 글