-
[Paper short review] OBJECT-AWARE CROPPING FOR SELF-SUPERVISED LEARNING 논문 리뷰Paper short review 2021. 12. 3. 23:40반응형
@ 굵은 글씨는 중요한 내용, 빨간 글씨는 내가 추가한 내용
https://arxiv.org/pdf/2112.00319v1.pdf
- 정리: self-superevised learning에서 data augmentation인 object-aware cropping 알고리즘을 통한 성능 향상
0. Abstract
최근 self-supervised learning의 핵심 요소는 self-supervised loss에서 positive example로 사용될 이미지의 sub-region을 선택하는 data crop이다. 기본 가정은 주어진 image에서 무작위로 crop하여 ojbect에 대한 정보를 얻는 것이다. 하지만 이는 object가 크고 주로 중심에 존재하는 ImageNet dataset외에 여러 객체가 다양한 위치에 존재하는 OpenImages나 COCO dataset에 대해서는 성능이 떨어진다.
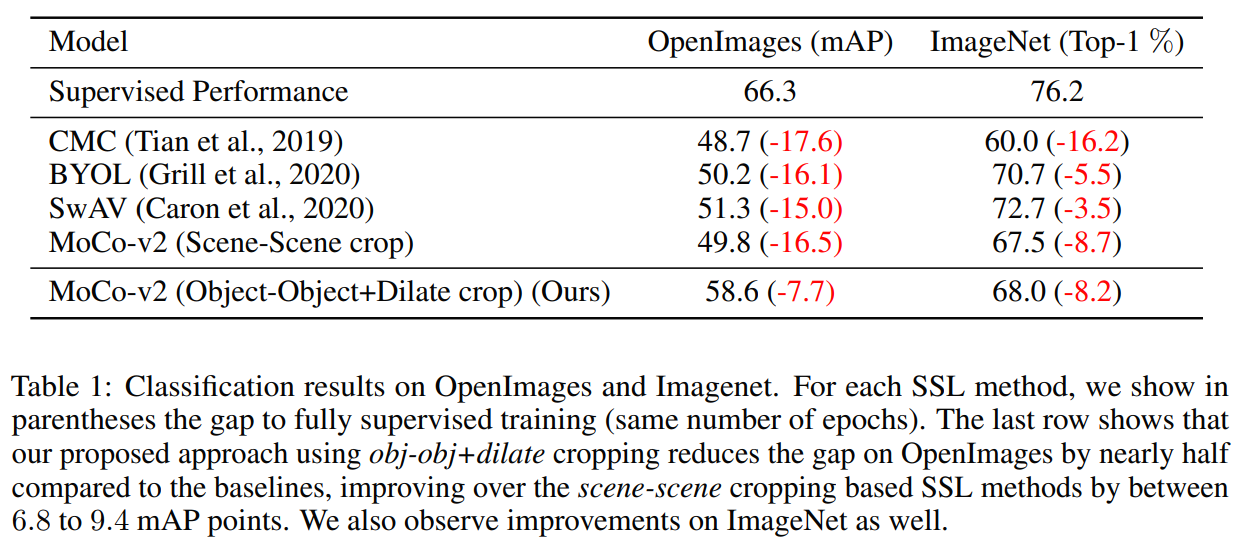
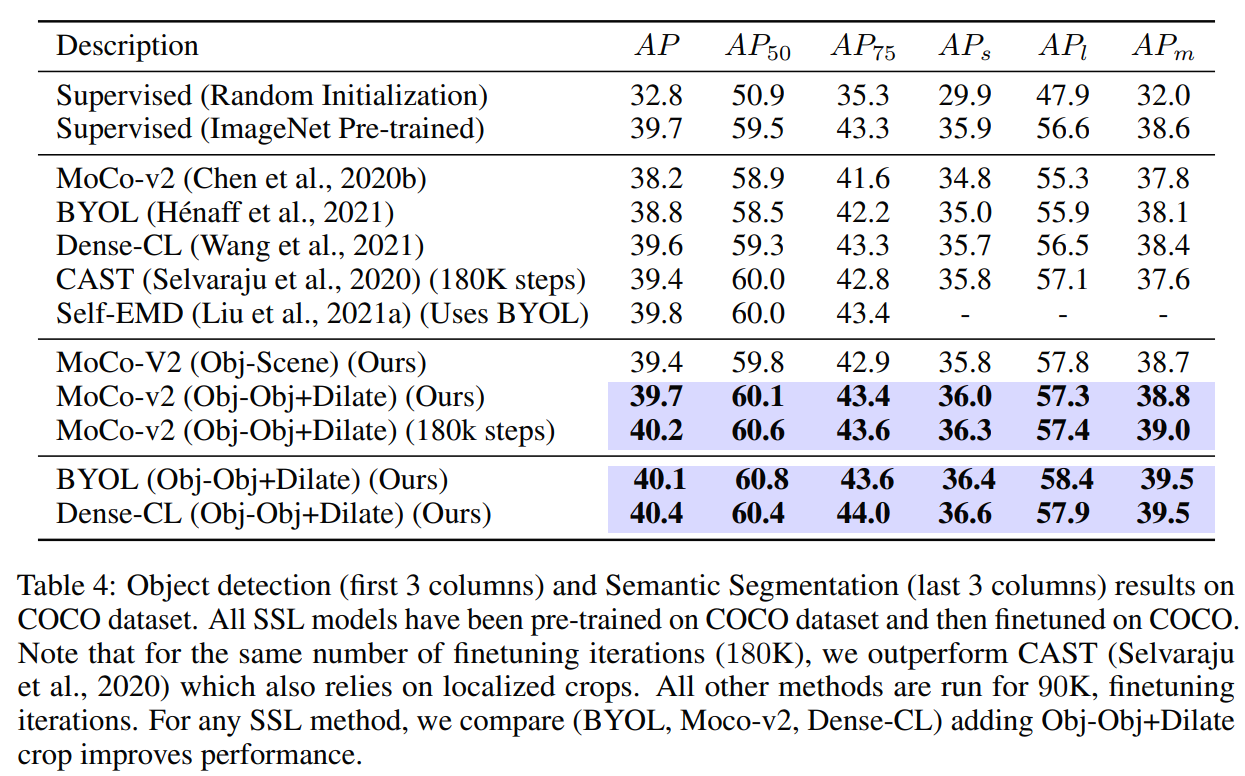
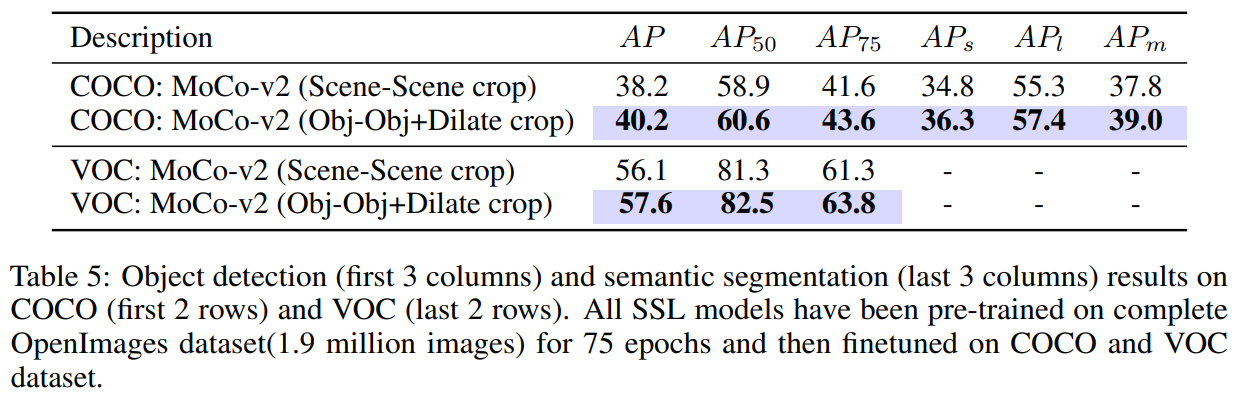
따라서 본 연구에서는, random crop을 object proposal 알고리즘에서 얻은 crop으로 대체하는 것을 제안한다. 이는 모델이 object와 scene 수준의 semantic representation을 모두 학습하도록 한다. Object-aware cropping을 통해 scene를 크게 개선할 수 있다 (OpenImages에서 기존에 비해 8.8 mAP 증가). 또한 SOTA self-supervised learning에 비해 COCO와 PASCAL-VOC의 object detection 및 segmentation task에서 성능을 크게 개선한다.
본 방법론은 간단하고 일반적이여서 대부분의 self-supervised learning에서 원활하게 통합될 수 있다.

3. PROPOSED APPROACH
Object crop 에 기반한 SSL방법(Self-Supervised Leanring) 모두 지도 학습보다 성능이 떨어진다. 이에 따라 우리는 1. crop에 object와 scene 정보를 모두 통합하는 것을 제안한다. Object 주위의 scene가 도움이 된다고 가정한다. 그러나 어떤 object 및 scene의 정보 통합이 가장 좋은지 명확하지 않기 때문에, 여러가지 실험을 수행한다. 우리의 주요 기여는 이 cropping 메커니즘을 달성하기 위한 간단하고 효과적인 접근법이다.
Object-awareness를 활성화하기 위해, 우리는 세 가지 object proposal 모델(BING, Edge-Boxes, unsuptervised object proposal method)을 고려한다.
BING proposal은 여러 object proposal을 output하며, 그 중 하나는 SSL loss에 대한 첫 번째 뷰로 무작위로 선택한다.
(a) Dilated object proposals (Obj-Obj+Dilate Crop):
Object에 공간적으로 가까운 scene 픽셀은 object와 positive 관계를 가질 가능성이 더 높다. 이러한 가정에 따라, 우리는 BING proposal을 확장하여 second view를 생성한다. Image size의 10% 혹은 20%만큼 box를 확장하여 random crop을 수행한다 (첫 번째 box의 크기를 확장하여 crop). 바뀐 dilation value δ는 통합되는 scene 정보의 양을 제어할 수 있게 한다 (대부분의 경우 10%의 값이 적합).첫 번째 view가 두 번째 view에 포함되지 않도록 원래 상자와 확장 상자 모두 무작위로 자르기됩니다. 쿼리 또는 키로 사용할 크롭은 임의로 선택할 수 있으며 개체 크롭과 확장 개체 크롭을 모두 키와 쿼리로 사용할 수 있습니다. 우리는 또한 장면 정보를 통합하기 위한 다른 그럴듯한 접근 방식인 아래에 나열된 다른 기준선을 고려한다.그러나, 실험을 통해 dilated crops이 최고 성능을 보이는 것을 확인할 수 있다.
(b) Scene-Scene Crop:
이미지에서 무작위로 두 개의 crop을 positive로 설정한다 (기존 SSL에서 사용되는 방법). 이는 openimages와 같은 dataset에 대해 성능이 떨어진다.
(c) Shifted object proposals (Obj-Obj+Shift Crop):
Obj-Obj+Dilate와 달리 두 번째 view는 첫 번째 box의 사전 지정된 거리 범위 내에서 random으로 선택된 box이다 (BING proposal). 사전 지정된 거리는 80-100픽셀, 100-120픽셀 등 몇 가지 범위에서 임의의 값을 선택한다.
(d) Random crop (Obj-Scene Crop):
첫 번째 view는 BING proposal이고, 두 번째 view는 scene level에서 일반 random crop이다. 이 방법은 object 및 scene level에서 정보를 제공하며, 우리는 이를 모델에 context 정보를 추가하기 위한 기준으로 사용한다.4. RESULTS


6. CONCLUSION
Random crop 대신 빠르고 효과적인 data augmentation인 object-aware cropping을 제안한다. 실험을 통해 우리의 object crop이 많은 CV task에서 성능을 크게 향상시킨다는 것을 확인할 수 있었다. 본 방법론은 대부분의 self-supervised learning에서 원활하게 통합될 수 있다.
My Discussion
Why this paper?
object detection이 논문명에 있었고 self-supervised learning 궁금하단 생각에 결정 (weakly learning을 본 후에 데이터부족을 해결하는? 논문에 부쩍 관심이 많아짐)
--> scene-level crops, purely object-level crops 뭔말인지 모르겠다..
--> 뭔가 쉬운데 어렵다,,,
--> self-supervised learning이 뭔지 몰라서 이해를 잘 못하는 것같다. 이거를 좀 더 공부하고 보면 훨씬 잘 읽히고 재밌을 듯 하다. 나중에 다시 읽어봐야지,,,,
반응형'Paper short review' 카테고리의 다른 글