-
[Paper short review] VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization 논문 리뷰Paper short review 2021. 12. 10. 15:22반응형
@ 굵은 글씨는 중요한 내용, 빨간 글씨는 내가 추가한 내용
- 정리: Swin transformer 개선 모델인 Swin transformer V2를 제안한다. 기존 모델의 기술적인 부분을 개선하고, 큰 모델에 전이할 때의 문제점을 개선한다. 이를 통해 classification, detection, segmentation, video action classification 4가지 CV task에서 SOTA를 달성한다.
0. Abstract
이미지 기반 virtual try-on task는 target 의류 아이템을 사람의 해당 영역으로 transfer하는 것을 목표로 하며, 일반적으로 해당 아이템을 원하는 신체 부위에 fitting하고, 그 warped 아이템(합성하려는 아이템)을 사람과 융합함으로써 해결된다. 이와 관련해서 많은 연구가 수행되고 있지만 낮은 해상도로 제한되어 있다 (EX. 256 x 192). 우리는 다음과 같은 이유로 제한이 생긴다고 생각한다: 해상도가 높아짐에 따라 warped 아이템과 원하는 (사람의) 영역 사이의 misaligned된 부분의 인위적인 것이 최종 결과에 나타난다.

기존 방법에 사용된 아키텍처는 고품질의 신체부위를 생성하거나 옷의 질감을 유지하는 데 성능이 낮다. 이를 해결하기 위해 1024 x 768개의 가상 try-on image를 성공적으로 합성하는 VITON-HD라는 새로운 virtual try-on 방법을 제안한다. 구체적으로, 먼저 virtual try-on을 위해 segmentation map을 추출한 후, target item을 주어진 사람의 몸에 대략 맞춘다. 다음으로, misaligned 영역을 처리하고 1024x768 input의 세부 정보를 보존하기 위한 ALIgnmentAware Segment (ALIAS) normalization과 ALIAS generator를 제안한다. 기존 방법과의 비교를 통해 VITON-HD가 정성적, 정량적으로 합성된 이미지 품질 측면에서 기존 성능을 크게 능가한다는 것을 입증한다.
3. Proposed Method
Model Overview.
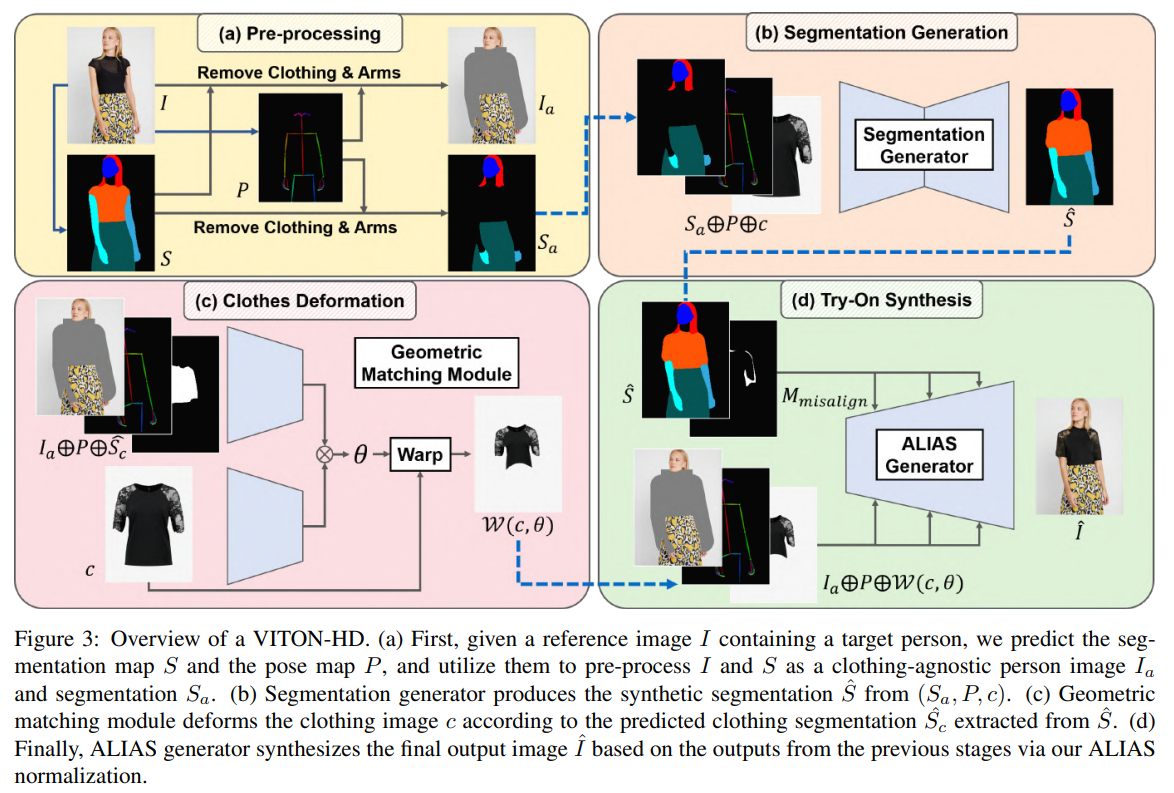
위의 그림은 VITON-HD의 아키텍처이다. 사람 이미지 I ∈ R^(3×H×W)와 의류 아이템 c ∈ R^(3×H×W)가 주어졌을 때, VITON-HD의 목표는 주어진 사람이 해당 의류 아이템을 입은 합성 이미지 I^을 생성하는 것이다.
(I, c, I^) triplets로 모델을 학습하는 것은 간단하지만, 이러한 dataset을 구축하기 어렵다. 대신 c를 이미 착용한 I인 (I, c, I)를 사용한다. (I, c, I)에 대한 직접 학습을 하는 것은 모델의 일반화 능력을 해칠 수 있으므로, 먼저 I의 의류 정보를 생략하고 input으로 사용하는 clothing-agnostic person representation(c에 대한 정보가 없는)을 구성한다. 우리의 새로운 clothing-agnostic person representation은 I(section 3.1)의 의류 정보를 제거하기 위해 개인의 pose map과 segmentation map을 모두 사용한다. 이 모델은 옷에 구애받지 않는 사람 representation에서 segmentation map을 생성하여 I^(section 3.2) 생성을 돕는다. 그런 다음 c를 변형하여 인체에 대략적으로 맞춘다(section 3.3). 마지막으로, 우리는 변형 후 misaligned 영역에서 잘못된 정보를 제거하는 ALIAS(Alignment-Aware Segment) normalization를 제안한다. ALIAS generator는 misaligned 영역을 의류 질감으로 채우고 의류 세부 정보를 유지한다(section 3.4).
3.1. Clothing-Agnostic Person Representation
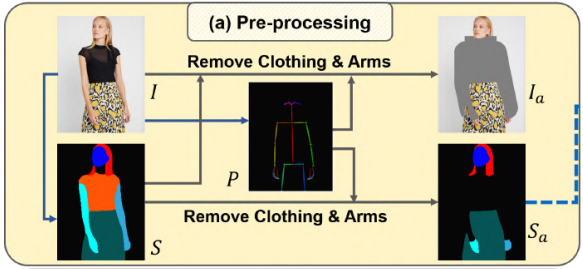
c와 c를 이미 착용하고 있는 사람 이미지 I를 쌍으로 학습시키기 위해, 옷에 대한 정보가 없는 사람 representation을 virtual try-on task에 활용했다 (c를 착용하고 있는 이미지 I에서 c를 제거하여 학습했다는 말인듯). 이는 다음 조건을 만족해야 한다.
- 교체될 원래 의류 아이템을 삭제해야 함
- 자세와 개인의 체형을 예측하기에 충분해야 함
- 개인의 정체성을 위한 영역은 보존해야 함 (Ex. 얼굴, 손 등)
Problems of Existing Person Representations.
사람의 체형을 유지하기 위해 옷의 정보를 완전히 제거하는 데에 어려움이 존재했음 -> 이는 테스트에서도 문제 발생
Clothing-Agnostic Person Representation.
각 단계의 input으로 clothing-agnostic image Ia와 clothing-agnostic segmentation map Sa를 제안하는데, 이는 의류 아이템 c의 형태를 제거하고 regenerate가 필요한 신체를 보존한다.
먼저 pretrained network를 통해 I의 segmentation map S ∈ L^(H×W)와 pose map P ∈ R^(3 × H×W)를 예측한다 (L은 의미 레이블을 나타내는 정수 집합이다 =segmentation 했다는 말). S는 교체할 의류 영역을 제거하고 이미지의 나머지 부분을 보존하는 데 사용된다. P는 손이 아닌 팔은 재생산이 어렵기 때문에, 팔을 제거하는 데 활용 된다. S와 P를 기반으로 모델이 원래 의류 정보를 완전히 제거하고 나머지 이미지를 보존할 수 있는 Ia와 Sa를 생성한다. 또한 생성 품질을 향상시키는 골격 구조를 나타내는 RGB 포즈맵 P에 Ia 또는 Sa를 연결한다.
3.2. Segmentation Generation
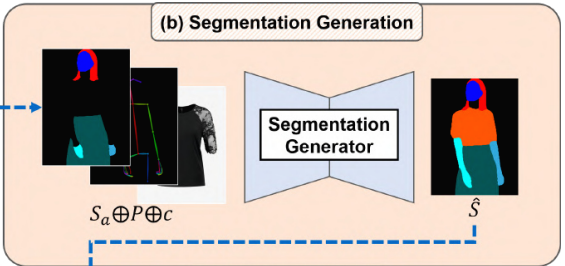
옷에 구애받지 않는 사람 표현(Sa, P)과 target 의류 아이템 c를, segmentation generator GS는 c를 착용한 기준 이미지에서 사람의 segmentation map S^∈ L^(H×W)를 예측한다. 우리는 원래 의류 아이템 정보가 완전히 제거된 S와 (Sa, P, c) 사이의 매핑을 배울 수 있도록 GS를 학습한다. GS의 아키텍처로서, 우리는 U-Net을 채택하고, GS의 총 손실 Ls는 다음과 같다.
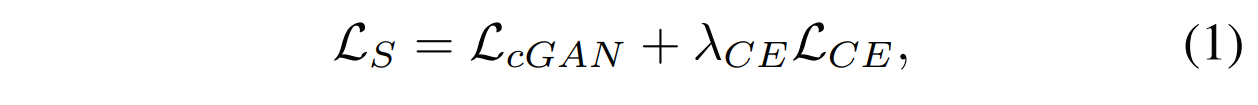
Lce와 Lcgan은 각각 S^과 S 사이의 pixel-wise cross-entropy loss와 conditional adversarial loss을 나타낸다. λce는 hyperparameter이다.
3.3. Clothing Image Deformation
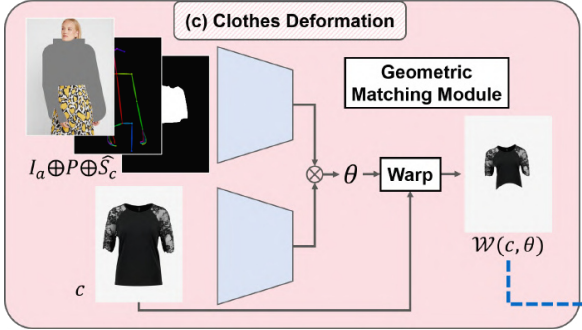
이 단계에서는 target item c를 S^의 의류 영역인 Sc^와 일치하도록 변형한다. 우리는 CPVTON에서 제안한 geometric matching module을 clothing-agnostic person representation (Ia, P)와 Sc^ 를 입력으로 사용한다. 먼저 (Ia, P)와 c에서 추출한 형상 사이의 상관 행렬이 계산된다. 상관 행렬을 입력으로 하여, 회귀 네트워크는 TPS 변환 parameter θ ∈ R^(2×5×5)를 예측하고, c는 θ에 의해 warped된다. 학습 단계에서 모델은 Sc^ 대신 S에서 추출한 Sc (segmentation map S에서 c의 영역)를 취한다. 모듈은 warped item과 I에서 추출한 옷 Ic(실제 이미지 I에서의 c영역) 사이의 L1 loss로 학습됩니다. 또한 warped 의류 이미지의 obvious distortions을 줄이기 위해 second-order difference constraint를 채택한다. 옷을 몸에 맞게 휘어지게 하는 overall objective function은 다음과 같다.
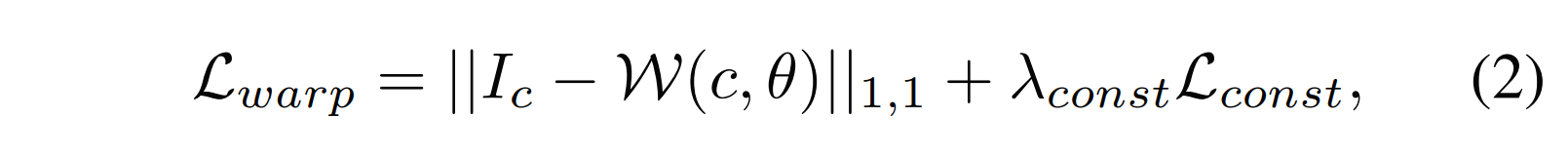
여기서 W는 θ를 사용하여 c를 변형시키는 함수이고, Lconst는 second-order difference constraint이며, λconst는 Lconst에 대한 parameter이다.
3.4. Try-On Synthesis via ALIAS normalization
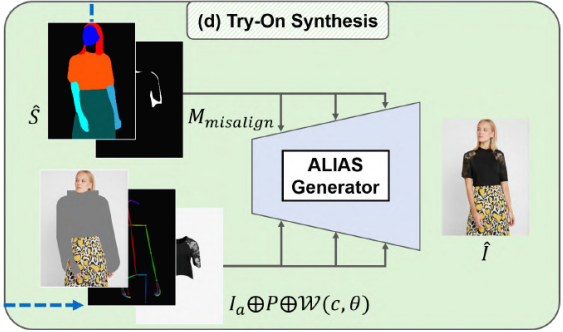
이전 단계의 output을 기반으로 최종 합성 이미지 I^를 생성하는 것을 목표로 한다. 전체적으로 우리는 (Ia, P)와 W(c, θ)를 융합한다. (Ia, P, W(c, θ))는 generator의 각 layer에 input된다. S^의 경우, ALIgnment-Aware Segment (ALIAS) normalization이라는 새로운 conditional normalization 방법을 제안한다. ALIAS normalization은 S^와 해당 영역의 mask를 활용하여 semantic 정보를 보존하고 misaligned 영역에서의 misleading information를 제거한다.
Alignment-Aware Segment Normalization.
hi ∈ R^(N×C i×Hi×Wi)는 i번째 layer의 activation이다 (N: batch, H: height, W: width, C: channel). ALIAS normalization에는 두 가지 input이 있다
- synthetic segmentation map S^
- the misalignment binary mask M_misalign ∈ L^(H×W) (Sc^에서 W(Mc, θ)는 제외)
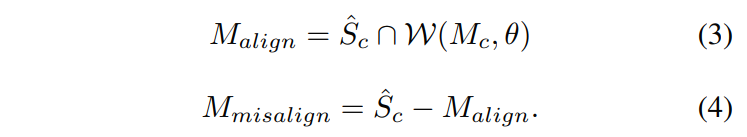
위의 수식을 포함한 ALIAS normalization을 시각화 하면 다음과 같다.
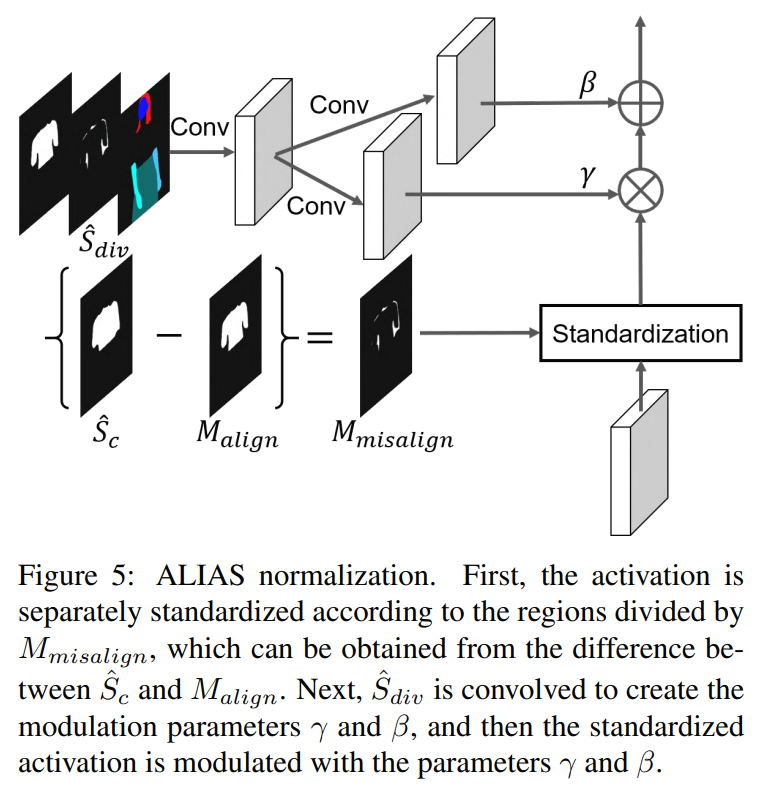
먼저 Eq. (3)과 Eq. (4)로부터 Malign과 Msalign을 얻는다. S^의 수정된 버전을 Sdiv^로 정의한다 (S^의 Sc^는 Malign과 Mimsalign으로 분리). ALIAS normalization은 Mmisalign 영역과 hi의 다른 영역을 별도로 표준화 한 다음 Sdiv^에서 추론한 affine 변환 파라미터를 사용하여 표준화된 activation를 modulate한다. e activation value at site (n ∈ N, k ∈ C i , y ∈ Hi , x ∈ Wi )는 다음과 같이 계산한다.
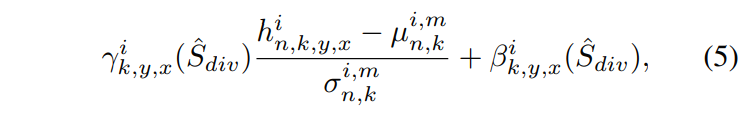
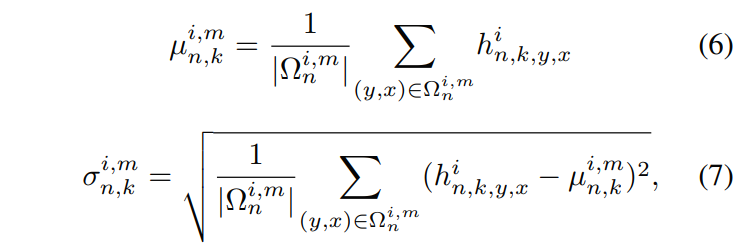
인스턴스 표준화 [26]와 유사하게, 활성화는 채널별로 표준화된다. 그러나 ALIAS 정규화는 채널 k의 활성화를 잘못 정렬된 영역과 다른 영역의 활성화로 나눈다.
이 방법은 misaligned 영역에서의 misleading 정보를 제거한다. 특히 the warped clothing image에서 misaligned regions은 옷의 질감과 무관한 배경과 똑같다. 이러한 영역에서 별도로 표준화를 수행하면 최종 결과에서 인위적인 결과를 유발하는 배경 정보가 제거된다. segmentation map서 유추된 affine 파라미터는 표준화된 활성화를 변조한다. 각 ALIAS normalization layer에 semantic 정보를 주입하기 때문에 최종 결과에서 human-parsing map의 레이아웃이 보존된다.ALIAS Generator.
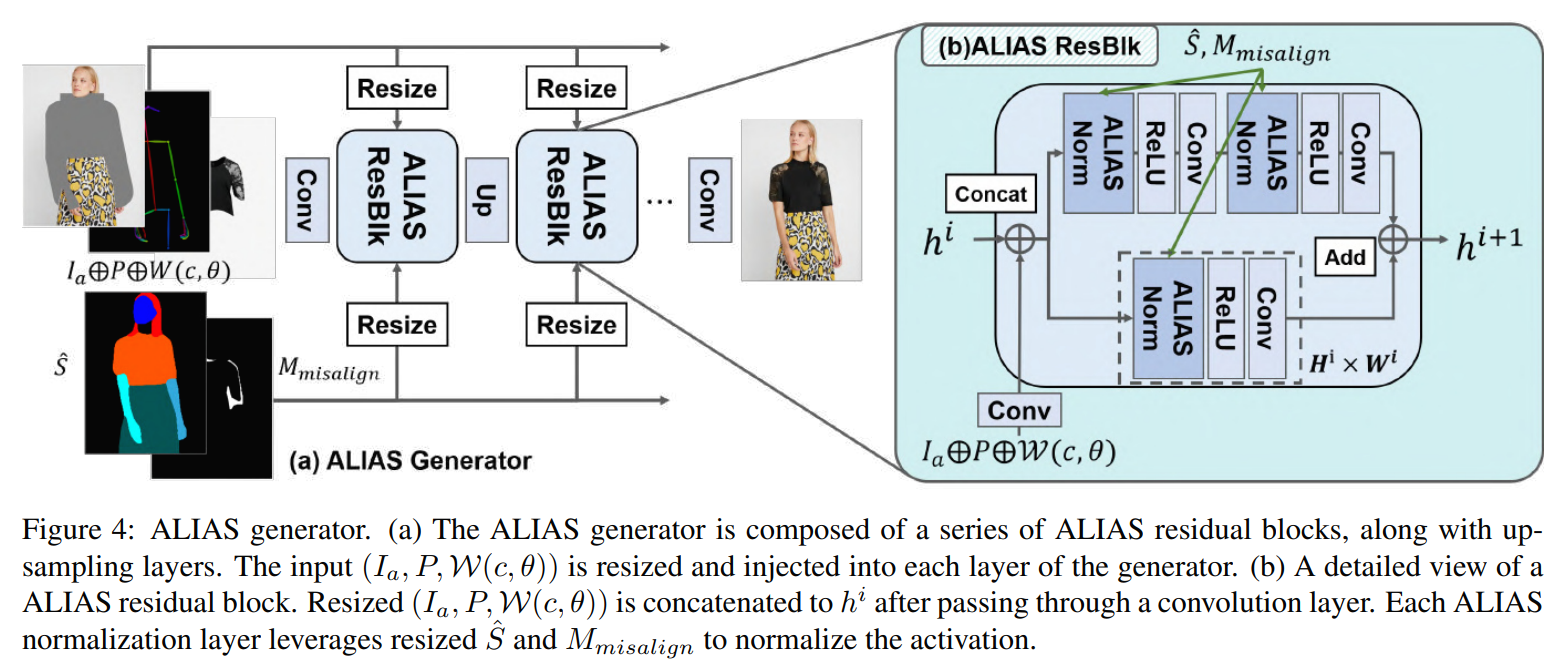
위의 그림은 encoder-decoder network의 encoder 부분을 제거하는 단순화된 아키텍처를 채택한 ALIAS generator의 아키텍처이다. Generator는 upsampling layer가 있는 residual blocks (ResBlk)을 사용한다. 각 ALIAS ResBlk는 3개의 컨볼루션 레이어와 3개의 ALIAS 정규화 레이어로 구성된다. ResBlks가 작동하는 해상도가 다르기 때문에 각 계층에 주입하기 전에 표준화 계층인 S^ 및 Mimsalign의 입력 크기를 조정한다. 마찬가지로, generator의 입력 (Ia, P, W(c, )))은 다른 해상도으로 크기가 조정된다. 각 ResBlk 전에 크기 조정된 입력(Ia, P, W(c, θ))은 컨볼루션 레이어를 통과한 후 이전 레이어의 활성화에 연결되며, 각 ResBlk는 연결된 입력을 활용하여 활성화를 세분화한다.
이러한 방식으로 network는 픽셀 수준에서 단일 미세 조정보다 의류 세부 사항을 더 잘 보존하는 특징 수준에서 다중 스케일 미세 조정을 수행한다. We train the ALIAS generator with the conditional adversarial loss, the feature matching loss, and the perceptual loss following SPADE [17] and pix2pixHD [28]. 모델 아키텍처, 하이퍼 파라미터 및 손실 함수에 대한 자세한 내용은 보충 자료에 설명되어 있다.
4. Experiments
4.1. Experiment Setup
4.2. Qualitative Analysis
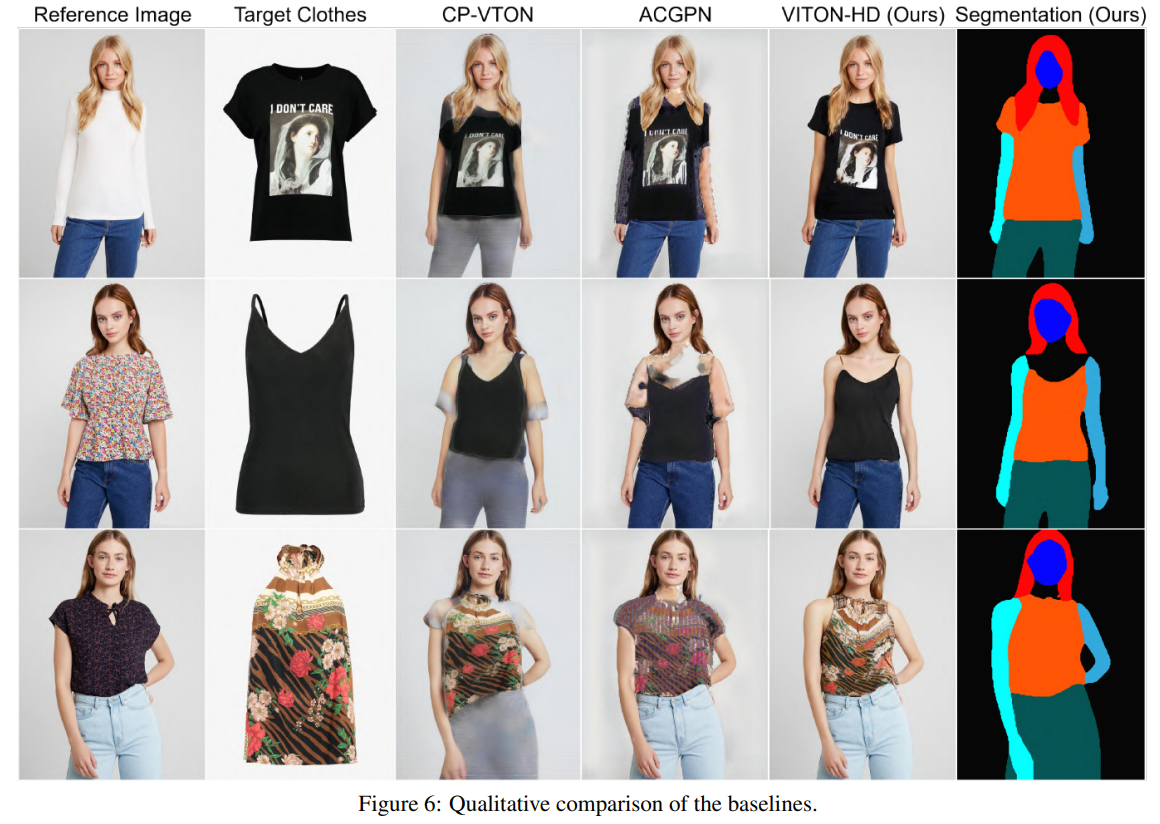
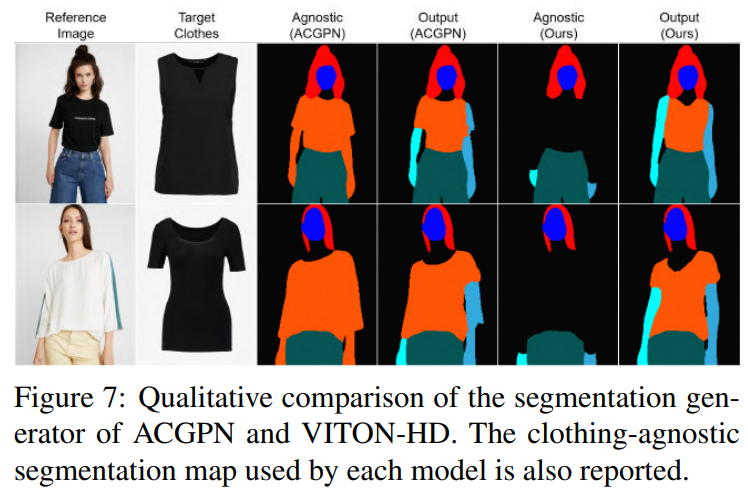
4.3. Quantitative Analysis
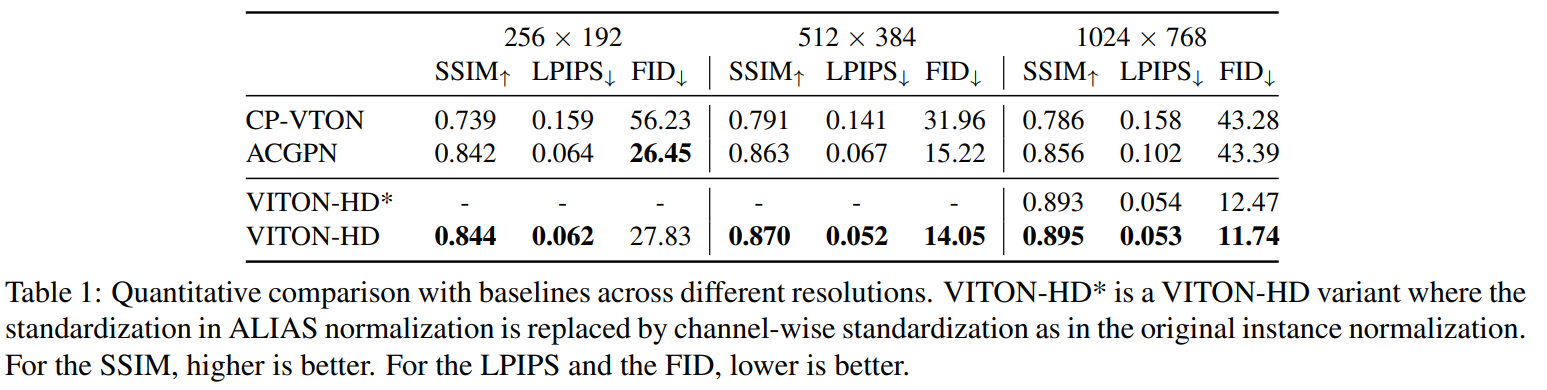
5. Conclusions
1024 x 768 해상도의 사실적인 virtual try-on image를 합성하는 VITON-HD를 제안한다. 제안된 ALIAS normalization는 misaligned 영역을 적절히 처리하고 semantic information를 ALIAS generator 전체에 전달할 수 있으며, multi-scale refinement를 통해 의류의 세부 사항(EX. 질감)을 보존한다. 정성적 및 정량적 실험은 VITON-HD가 큰 차이로 기존의 방법들을 능가한다는 것을 입증한다.
My discussion
어제 유튜브에서 주재걸 교수님이 나온 영상을 보고, 최근 cvpr에 승인되었다는 것을 보고 간단히 읽어보자 결정
--> I^의 dataset을 찾기 어려워 I를 사용했다는 점이 신기함
--> ALIAS generator는 misaligned 영역을 의류 질감으로 채운다고 하는데, 더 읽어봐야 하긴 하겠지만, 그렇다면 옷의 형태??가 변화되는게 아닌가?
--> try-on 분야는 처음 접해봤는데 신기 + GAN의 확장 영역은 무궁무진 하구나 생각이 듬
반응형'Paper short review' 카테고리의 다른 글