-
[Document Enhancement] DE-GAN: A Conditional Generative Adversarial Network for Document Enhancement 번역 및 설명Paper review/Document Enhancement 2022. 1. 12. 15:01반응형
@ 굵은 글씨는 중요한 내용, 빨간 글씨는 내가 추가한 내용
https://arxiv.org/pdf/2010.08764.pdf
- 정리: 문서 이미지 향상 task에서 처음으로 GAN을 사용 및 loss 함수 추가, SOTA 달성
0. Abstract
- 디지털화 된 문서는 다양한 손상을 받고, 이는 OCR의 성능을 저하시킨다.
- 본 논문에서는 conditional GAN(cGAN)을 사용하여 손상된 문서 이미지를 복원하는 endo-to-end 프레임워크 DE-GAN(Document Enhancement Generative Adversarial Network)을 제안한다.
- 문서 이미지 강화 task에서 처음으로 generative adversarial deep networks 사용
- 다양한 task(문서 정리, 이진화, 디블러링 및 워터마크 제거)에서 DE-GAN이 고품질의 향상된 문서 생성
- DIBCO dataset에서 SOTA에 비해 일관된 개선을 제공하여 이상적인 이미지로 복원 가능
- 실험 결과를 통해 다른 문서 강화 task에 활용될 수 있음을 입증
3. PROPOSED APPROACH
- 문서 향상 task를 iamge-to-image로 다루고, 손상된 이미지를 고려하여 깨끗한 이미지를 생성하는 것이 목표
- DEGAN(for Document Enhancement conditional Generative Adversarial Network)이라 부른다.
- cGAN 사용
- GAN은 두 개의 신경망, 생성기 G와 판별기 D로 구성
- 생성기 G는 무작위 노이즈 벡터 z에서 이미지 y,
 로의 매핑 학습
로의 매핑 학습 - 판별기 D는 G에 의해 생성된 fake 이미지와 real 이미지를 구별 학습
- y가 주어지면 D는 확률값인
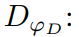
 를 출력하여 fake인지 real인지 판별
를 출력하여 fake인지 real인지 판별 - 이 두 네트워크는 min-max game으로 서로 경쟁하며 학습
- G는 real에 가까운 이미지를 생성하여 판별자를 속이는 것을 목표로 하지만 D는 이미지의 real, fake를 판별하는 것을 목표로 한다 (= 적대적 학습).
- cGAN은 추가 매개 변수 x를 도입한 것을 제외하고 동일하다. 이는 조건화 이미지이다.
- G는 관찰된 이미지 x와 무작위 노이즈 벡터 z에서
 로의 매핑을 학습
로의 매핑을 학습 - D는 프로세스를
 를 학습
를 학습
- G는 손상된(watermarked) image lw가 주어지면 clean image Ic를 생성한다.
- G는 ground truth image GT에 매우 가까운 이미지를 생성하는 것을 목표로 한다.
- 손실함수는 다음과 같음

- 이 손실함수를 통해 G는 GT와 유사한 이미지를 생성해서 D를 속여야 한다.
- 하지만 내용이 보존되는 지 알 수 없다 (=D를 속이기 위한 시각적 품질만 향상되고, document 내용은 손실될 수 있음)
- document 내용 보존을 위해, Ic와 GT 사이에 추가 log loss 함수를 사용
- 이 추가 손실은 학습 속도를 높인다.
-
- 추가 손실함수는 다음과 같음
- 최종 제안 손실 함수는 다음과 같음
- text cleaning에서 λ=100, watermark removal과 document binarization에서 λ=500
3.1 Generator
- G는 image-to-image translation을 수행한다.
- 일반적으로 이 task에는 auto-encoder자동 인코더 모델이 사용된다.
- 특정 layer까지 convolutional과 downsampling을 수행하는 encoder
- 그 후, convolution과 upsampling을 수행하는 decoder
- 하지만 해당 모델은 단점이 존재한다.
- downsampling으로 인해 많은 정보가 손실됨에 따라, 입력과 동일한 크기의 이미지를 예측할 때 모델이 복구하는 데 어려움이 존재함
- 이미지 정보 흐름이 병목 현상을 포함한 모든 계층을 통과함에 따라 대량의 중복 발생 (입력 및 출력이 많은 동일한 픽셀을 공유하고 있음) (down sampling이 진행됨에 따라 output이 input과 동일한 크기를 갖게 하기 위해 필요한 픽셀보다 더 많이 input하고, 중복으로 겹쳐서 convolution을 수행함)
- 이를 해결하기 위해 U-net이라는 모델의 구조를 따라 skip connection 사용
- skip connection은 두 layer마다 추가되는데, 기울기가 사라지고 폭발하는 문제를 방지하기 위해 매우 깊은 모델을 훈련할 때도 스킵 커넥션을 사용
- batch normalization layer 추가
- G의 구조는 다음과 같다.
3.2 Discriminator
- G는 생성된 이미지가 실제일 확률을 포함하는 2D 매트릭스를 출력하는 6개의 컨볼루션 레이어로 구성된 단순 완전 컨볼루션 네트워크(FCN)이다.
- D의 구조는 아래와 같다.
- lw와 lc혹은 lw와 GT를 입력 받는다.
- 256 x 256 x 2 shape
- 마지막 layer output : 16 × 16 × 1
- G에서 나온 이미지 lc인 경우 D는 0, 실제 GT인 경우 D는 1을 출력해야 한다.
- 마지막 layer는 sigmoid
- lw가 주어지면, cleaning하기 위해 G를 사용하고, D는 경쟁 학습을 통해 G가 더 나은 결과 lc를 만들도록 한다.

3.3 Training process
- DE-GAN 학습 방법
- 256×256 크기의 저하된 이미지에서 패치를 가져와 G 입력
- 생성된 이미지 Ic는 GT와 lw와 함께 D에 입력
- 식 (3)처럼 D는 G의 "fake"를 탐지하고, G는 "real"과 구별할 수 없는 이미지를 생성하도록 학습
- optimizer=Adam, lr=1e -4

4. EXPERIMENTS AND RESULTS
4.1 Document cleaning and binarization
- Noise Office Database 사용
- 112개의 학습 이미지에서, 256 x 256 픽셀 크기의 패치 추출 -> 1356쌍의 패치 생성
- FCN과의 비교 결과

- 모델 결과 예시

- DIBCO 2013 Dataset에서의 SOTA 모델 비교 결과
- DE-GAN이 우수하다는 것을 확인할 수 있음


- 방법론 비교 결과 예시


- 최신 DIBCO 데이터 세트인 DIBCO 2017에서 모델 비교 실험 결과


- 최신 방법론과의 비교 결과
- 기존 SOTA 방법론은 많은 사전 처리 및 후처리 단계를 통합한 방법
- 반면 DE-GAN은 추가적인 처리 단계 없이 여러 데이터 세트에서 우수한 능력을 보임


4.2 Watermark removal
- Dense한 워터마크와 스탬프가 존재하는 dataset 구축
- 1000쌍(Dense한 워터마크와 스탬프가 있는 문서의 이미지와 깨끗한 버전) 생성
- 데이터셋 생성 코드는 https://github.com/dali92002/watermarking-documents/blob/master/Watermarking.ipynb에서 확인할 수 있다.

- 결과는 다음과 같다.

- 결과 예시

4.3 Comparison with other GAN models
- pix2pix 모델을 기반으로 한다 (더 깊은 생성기 G와 추가 손실 사용).
- 본 모델과 GAN, pix2pixHD의 비교 실험 수행.
- 높은 성능 달성


4.4 Document deblurring
- DE-GAN은 이진화, 잡음 제거 및 워터마크 제거와 같은 다양한 문제에서 SOTA를 달성한다.
- 더 어려운 task인 deblurring에서 실험을 수행한다.
- pix2pixHD와 비슷한 결과를 제공하지만, 일부 문자를 예측하는 것은 더 정확하다.
- But) 사용된 데이터 세트는 300x300px 이미지 패치이지만, pix2pixHD는 더 큰 패치에서 작동
- pix2pixHD와 비슷한 결과를 제공하지만, 일부 문자를 예측하는 것은 더 정확하다.


4.5 OCR evaluation
- Tesseract OCR을 사용하여 테스트 수행
- 문자 오류율: 0.37(lw) -> 0.01 (lc)

5. CONCLUSION
- 손상된 문서 이미지를 복원하기 위해 DE-GAN이라는 문서 강화 생성 적대적 네트워크 제안
- DE-GAN은 더 깊은 생성기와 다른 추가 손실(adversarial + log)을 가진 네트워크
- 문서 강화 task를 위한 GAN의 첫 적용
- 밀도 높은 워터마크(또는 스탬프) 제거인 문서 개선에서의 새로운 문제 제안
- SOTA를 능가하는 성능
- 제안 방법이 기준 OCR 성능을 큰 폭으로 향상시킨다.
- 향후 연구로, 판별기 부분에 OCR 평가 추가함으로써 판별자에게 본문을 읽는 능력을 주어 그것이 진짜인지 가짜인지를 결정할 수 있도록 함
- 이를 통해 더 읽기 쉬운 이미지를 생성하도록 학습될 것
- 더 많은, 다양한 손상이 발생하는 모바일 캡처 문서에서 DEGAN의 성능 테스트
My Discussion
--> 사실 그냥 pix2pix를 documnet image에 적용했다 + loss함수를 추가했다 뿐 별거 없음
--> 20년도 document 논문에 GAN을 사용한게 많은듯함
--> 근데 20년도 IEEE Transactions on Pattern Analysis and Machine Intelligence 실림 (Q1, 상위 1%이내)
--> 인용수도 15회뿐
반응형

