-
[Document Enhancement] BEDSR-Net: A Deep Shadow Removal Network From a Single Document Image 번역 및 정리 (BEDSR-Net)Paper review/Document Enhancement 2021. 11. 4. 17:21반응형
@ 굵은 글씨는 중요한 내용, 빨간 글씨는 내가 추가한 내용
https://arxiv.org/pdf/2010.04159.pdf
주요 기여:
- 최초로 딥러닝을 문서 shadow 제거 알고리즘에 적용
- 문서 shadow dataset 구축
0. Abstract
대부분의 기존 문서 이미지 shadow 제거 알고리즘은 hand-crafted heuristics이며 특징이 다른 문서에 강건하지 않다.
본 논문은 문서 이미지 shadow 제거를 위한 Background Estimation Document Shadow Removal Network (BEDSR-Net)를 제안한다. Background estimation module(BE-Net)은 문서의 global 배경색을 추출하기 위해 설계되었다. 배경색을 추정하는 과정에서 module은 배경 및 전경 픽셀의 공간 분포에 대한 정보도 학습한다. 이러한 정보를 attention map에 encoding한다. 예상 배경색 및 attention map을 사용하여 shadow removal 네트워크(SR-Net)는 이미지를 더 잘 복구할 수 있다.
또한 합성 이미지에 대해 훈련된 모델이 실제 사진에 대해 여전히 유효하다는 것을 보여주며, shadow 이미지 dataset을 제공한다.
실험을 통해 BEDSR-Net이 문서 이미지의 시각적 품질과 가독성을 모두 향상시키는 데 있어 기존 방법을 능가한다는 것을 보여준다.
1. Introduction
문서를 디지털화할 때, 스캐너 혹은 카메라를 사용한다. 스캐너는 우수한 품질을 보이지만 카메라는 그렇지 못한다.
카메라를 통한 문서 디지털화는 두 가지의 문제가 존재한다.
- 카메라의 원근법으로 인해 문서가 직사각형이 아닌 왜곡된 형태를 가질 수 있고, 문서가 접히거나 구부러질 수 있다.
- 카메라나 손에 의해 그림자가 생기는 경우 품질이 아주 저하된다.
본 논문은 캡처된 문서의 품질과 가독성을 향상시키기 위한 문서 이미지의 그림자 제거 문제를 다룬다.

그림자는 vision 알고리즘의 성능을 저하시키기 때문에 그림자 제거는 computer vision task에서 중요한 문제이다.
대부분의 기존 문서 그림자 제거 알고리즘은 문서 이미지의 특정 특징을 탐색하기 위해 일부 heuristics을 사용한다. 이는 특징이 비슷한 문서에서는 잘 작동하지만 다른 문서에는 강건하지 않다. 위의 예시에서 보이듯이 (d)는 그림자의 경계에 흔적이 남아있고, (e)는 색상이 지워지고, 일부 밝은 그림자가 남아있는 것을 확인할 수 있다.
heuristics을 제거하기 위해 딥러닝이 vision task에 많이 사용되고 있다. 그러나 자연 이미지가 아닌 문서 이미지 shadow 제거를 위한 연구는 수행되지 않았다.
ST-CGAN은 최첨단 자연 이미지 shadow 제거 방법이다. shadow image, non shadow image, shadow mask dataset이 주어지면 shadow detection 및 제거 작업을 동시 수행하는 end-to-end 아키텍처를 사용한다.
자연 이미지 shadow 제거 방법을 문서 이미지에 사용하는데에는 두 가지 문제가 존재한다.
- 학습을 위한 많은 데이터셋이 필요하다.
- 이러한 방법은 문서 이미지의 톡징을 이용하지 않기 떄문에 성능이 최적이 아니다. 위의 그림의 (f)가 ST-CGAN을 문서 이미지에 적용한 것이고, 적절히 제거하지 못하는 것을 확인할 수 있다.
최근의 shadow 제거 방법은 ST-CGAN보다 우수하지만 사전 훈련된 모델을 사용하는 경우가 많고, 문서 이미지의 특징을 고려하지 않는다 (=문서 이미지에 적용할 때, ST-CGAN과의 동일한 문제가 발생함).
본 논문은 문서 이미지 shadow 제거를 위한 딥러닝 기반 접근방식을 제안한다.
관련 데이터셋이 많지 않아 합성 이미지를 사용한다. 이는 실험을 통해 실제 이미지에 유효하다는 것을 보인다.
Bako가 제안한 문서 이미지의 특징을 활용하여 문서의 global 배경색을 추정하기 위한 네트워크 module을 제안한다.
global 속성을 탐색하여 배경 추정 module은 그림자의 위치에 대한 정보를 attention map 형태로 탐색한다.
예상 배경색과 attention map을 모두 사용하여 shadow 제거 module은 작업을 훨씬 더 잘 수행할 수 있다.
실험을 통해 시각적 품질이 기존 방법을 능가하고 가독성 또한 향상시키는것을 확인할 수 있다. 그 예시는 위의 그림 (c)에서 확인할 수 있다.
우리의 기여는 다음과 같다.:
- 문서 이미지의 shadow 제거를 위한 최초의 딥러닝 접근법을 제안한다. 이는 SOTA를 달성한다. 문서 이미지의 특정 속성을 탐색하여 먼저 배경색과 attention map을 추정한다 (이는 이미지 품질 개선 및 모델 파라미터 감소에 도움). 또한 attentiion map을 탐색하여 제안된 모델은 학습을 위한 shadow mask가 필요하지 않다.
- shadow image, non shadow image 및 shadow mask로 구성된 대규모 이미지 dataset을 생성한다.
- 합성 이미지에 대해 학습된 모델이 실제 이미지에 대해 효과적이라는 것을 보인다.
2. Related work
2.1. Shadow removal for natural images
기존 자연 이미지 shadow 제거 방법은 자연 이미지에 대해 사전 훈련된 VGG를 백본으로 사용하기 때문에 문서 이미지에 적합하지 않다. ST-CGAN은 SOTA를 달성하지만 문서 이미지용으로 특별히 설계되지는 않았다. 따라서 뒤의 실험에서도 볼 수 있듯이 문서 이미지에 대해 재학습을 한 후에도 문서 이미지 shadow 제거에 대한 성능은 최적이 아니다.
2.2. Shadow removal for document images
문서 이미지 shadow 제거 방법 중 하나는 고유 이미지 개념을 기반으로 하며, 반사 요소가 유사한 영역에서 휘도(밝기) 대비를 줄임으로써 그림자를 제거하는 것이다. 그러나 이는 색상 변화를 유발하고, 훨씬 더 밝은 결과를 보인다.
다른 방법은 이미지를 3D point cloud로 표시하고 visibility detection 방법을 사용하여 복구할 픽셀을 선택하여 문서 이미지의 품질을 향상시키는 것이다. 그러나 이는 결과에 그림자 가장자리가 남아 있는 경우가 많다.
또 다른 방법은 일정한 배경색을 가정하여 문서 이미지 shadow 제거에 direct interpolation을 사용하는 것이다. 각 패치에 대한 global 배경색과 로컬 배경색 사이의 비율을 계산하여 shadow map을 얻은 다음 이를 사용하여 입력 shadow iamge를 조정한다. 이러한 방법은 배경 영역 탐지 후 나머지 부분에서 interpolation을 수행하기 떄문에 문서가 숫자의 큰 영역을 포함하거나 그림자의 큰 영역에 가려질 때 실패한다 (배경으로 인식해버린다는 말).
본 논문은 단일 문서 이미지에서 그림자를 제거하는 딥러닝 방법론을 제안한다.
3. Method
학습 dataset D={S_i,N_i}는 N개의 image 쌍 (S_i,N_i)로 구성된다. S_i는 shadow image, N_i는 non shadow image.
학습 후 BEDSR-Net은 Ψ_BESR(S)를 생성한다. 이는 input으로 S를 받고, ouput으로 N˜ (N 추정)을 반환한다.

위의 그림은 BE-Net (Background Estimation Network)와 SR-Net (Shadow Removal Network)로 구성된 BEDSR-Net을 보여준다.
input 문서 shadow 이미지 S가 주어졌을 때, BE_Net는 문서의 global 배경색 b˜와 각 픽셀에 대해 non shadow 배경에 속할 확률을 나타내는 attention map H˜ (그림자가 아닐 확률)를 추정한다 ( b˜, H˜ ) = Ψ_BE(S).
shadow image S와 BE-Net의 output, ( b˜, H˜ )가 주어졌을 때, SR-Net은 non shadow image N˜=Ψ_SR(S,( b˜, H˜ ))를 최종 출력으로 예측한다.
3.1. Background Estimation Network (BE-Net)
문서의 배경색을 복구하고 shadow 제거 프로세스를 지원하기 위한 네트워크다.
기존 Bako는 색상 분포를 분석하여 배경색을 추정한다 (heuristics 방식).
BE-Net은 shadow image S를 input으로 deep network를 통해 배경색 b˜를 추정한다.
BE-Net 학습을 위해 dataset D의 각 문서 이미지 쌍에 대한 실제 배경색 bi를 알아야 한다. 다음 절차를 통해 실제 배경색을 구한다.
- non shadow image Ni의 픽셀을 intensity에 따라 두 그룹으로 군집화한다. EM(Expectation Maximization)이 포함된 GMM(Gaussian mixture models을 사용한다.
- 문서의 배경색은 보통 글자보다 더 밝다. 따라서 강도가 높은 클러스터를 배경 그룹으로 사용한다.
- 글자보다 배경이 어두운 경우 따로 처리한다.
Shadow image Si와 배경색 bi를 고려할 때, 다음을 최소화하여 BE-Net을 지도 학습으로 학습시킬 수 있다.
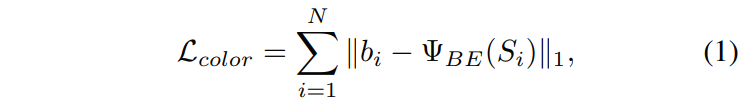
loss 함수 학습을 통해 예측 배경색 bi˜=Ψ_BE(Si)가 실제 배경색 bi에 가까워진다.
BE-Net는 4개의 conv layer로 구성되며, 그 다음 global max pooling layer와 Fully connected layer로 구성된다. Conv layer는 input shadow image에서 feature를 추출한다. 각 feature map을 value로 요약하기 위해 global pooling을 사용한다. Global pooling을 사용하여 conv layer와 FC layer를 연결함으로써 네트워크는 크기가 다른 이미지를 처리할 수 있다.
배경을 추정하는 과정에서 BE-Net은 이미지들의 공간 분포도 학습하며, shadow의 잠재적 위치를 표시하기 위한 추가 단서를 제공한다. 이 정보를 활용하기 위해 BE-Net의 마지막 conv layer의 feature map에 Grad-CAM 방법을 적용하여 attention map을 추출한다.
더보기CNN 모델이 어디에 주목하고 있는지를 시각화 해주는 weak supervised learning 알고리즘으로 CAM(2016)과 Grad-CAM(2017)과 같은 방법이 존재한다.

위 그림과 같이 학습된 네트워크가 이미지를 개라고 판별할 떄와 고양이라고 판별할 때, 각각 이미지에서 주목하고 있는 영역이 다르고, 이를 시각화 해주는 것이다.
Attention map은 shadow image에서 non shadow 배경 (red=그림자X)과 other(blue=그림자O) 픽셀을 잘 캡쳐한다. 또한 attention map은 그림자 위치에 대한 정보를 나타내며 shadow mask 역할을 할 수 있다.
다른 네트워크와는 달리, 학습을 위해 ground truth shadow mask가 필요하지 않다 (Si와 Ni만 필요함).
3.2. Shadow Removal Network (SR-Net)
shadow image에서 non shadow image를 얻기 위해 이러한 task에 좋은 성능을 보인 conditional generative adversarial networks (cGANs)를 사용한다. cGAN 모델은 generator G롸 discriminator D로 구성되며, conditioning variable이 주어졌을 때, G는 D를 속이는 진짜같은 이미지를 생성하는 것을 목표로 하고, 반면 D는 G가 생성한 이미지를 실제 이미지와 구별하는 것을 목표로 한다. 이를 통해 실제 이미지와 구별할 수 없는 결과를 생성하게끔 G를 학습한다.
Generator G의 경우 encoder와 decoder로 구성된 Fully connected network인 U-Net을 사용한다. Decoder의 feature는 각 공간 해상도의 skip connection을 통해 encoder의 feature와 결합한다. encoder, decoder 모두 5-level hierarchy를 사용한다. generator G는 Si, bi˜, attention map H˜을 input으로 연결한 후 non shadow image Ni˜= G(Si , bi˜ , Hi˜)를 예측한다. discriminator D에 대해서는 Markovian discriminator (PatchGAN)를 사용한다. D의 입력은 shadow image Si와 쌍으로 구성된 non shadow image Ni의 6채널 연결이다.
SR-Net 학습에는 다음과 같은 loss 함수가 사용된다.
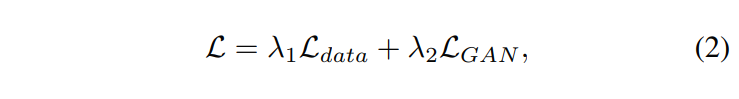
여기서 L_data는 실제 이미지로부터 예측된 non shadow image의 편차를 측정한다.

L_GAN은 G와 D의 사이에서 GAN의 loss이다.

Adam은 최적화에 사용된다. 파라미터는 경험적으로 λ1=1, λ2=0.01로 설정된다. 학습 후 generator G는 SR-Net의 output, 즉 , Ψ_SR ≡ G를 생성하는 데 사용된다.
4. Datasets
딥러닝 학습을 위해 shadow image와 non shadow image가 쌍으로 필요하다.
아래는 문서 shadow 제거 dataset 요약표이다.

사용가능한 문서 shadow dataset 4.1. Synthetic document shadow removal dataset
다양한 data을 생성하기 위해 Blender와 파이썬을 활용한다.
970개의 문서 이미지를 수집하였고, 각 문서에 대해 조명, 그림자를 통해 여러개의 그림자 이미지를 합성하여 총 8309개의 쌍의 데이터를 생성했고, 학습 7533쌍, validation 776쌍을 사용한다.
이 dataset을 SDSRD(Synthetic Document Shadow Removal Dates)라 하고, 아래는 그 예시이다.
SESRD는 BEDSR-Net 학습에 사용되고, 학습용 BEDSR-Net에는 shadow mask가 필요하지 않다. (ST-CGAN을 학습하려면 shadow mask가 필요하기 때문에 생성한다.)

4.2. Real document shadow removal dataset
실제 이미지를 평가하기 위해 RDSRD(Real Document Shadow Removal Dataset)을 수집했다.
dataset은 종이, 신문 등 25개의 문서의 540장의 이미지로 구성되며, 아래는 그 예시이다. 이 data는 평가에만 사용한다.

5. Experiments
5.1. Compared methods and evaluation metrics
성능 비교를 위해 SOTA 방법 4가지와 ST-CGAN+BE-Net인 ST-CGAN-BE를 사용한다 (아래는 ST-CGAN-BE 아키텍처).

시각적 품질과 내용 보존 두 관점에서 평가한다. 시각적 품질은 Peak Signal-to-Noise Ratio (PSNR)와 Structural Similarity (SSIM)를 사용하여 평가한다. 내용 보존은 Optical Character Recognition (OCR)을 사용하여 평가한다.
5.2. Quantitative evaluation
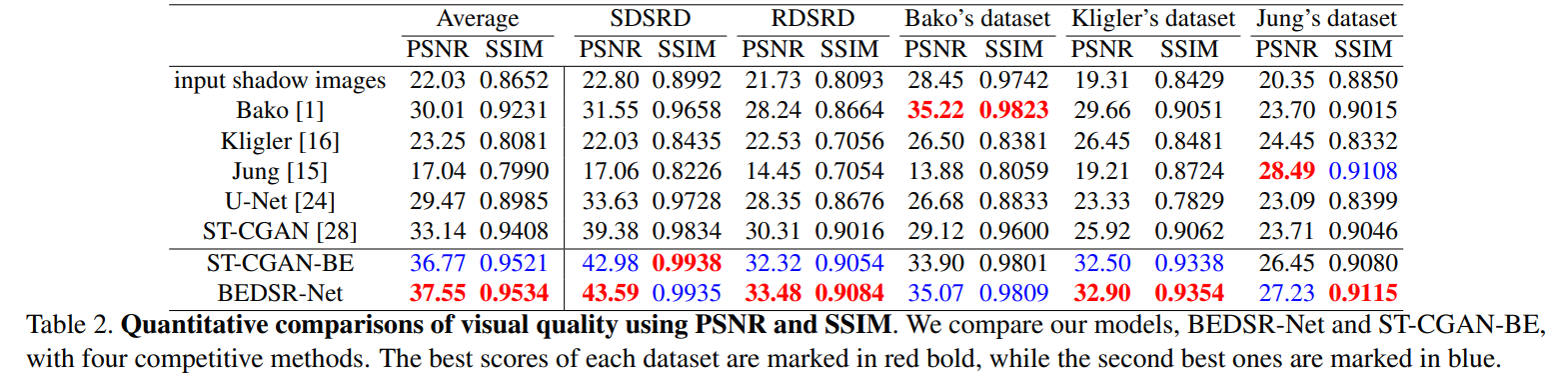
위의 표는 PSNR과 SSIM 측면에서의 정량적 비교 결과이다. BEDSR-Net이 대부분의 dataset에서 SOTA를 달성하는 것을 확인할 수 있다. Bako와 Jung은 각 dataset에 대해 높은 성능이지만 다른 dataset에 대해서는 낮은 성능을 달성하는 것을 볼 수 있다 (특정 문서에만 성능이 좋음). 우리 방법은 특성이 다른 이미지에 안정적이고 좋은 결과를 제공하기 때문에 이전 방법보다 더 강건하고 할 수 있다.
BEDSR-Net은 U-Net 기반이고 U-Net을 큰 차이로 능가하는 것을 알 수 있다.
ST-CGAN에 비해 ST-CGAN-BE의 우수한 성능은 배경 추정 module의 중요성을 보여준다.
BEDSR-Net(19.8M)은 ST-CGAN(38.9M)보다 적은 매개변수로 더 나은 성능을 달성한다.
5.3. Qualitative evaluation on visual quality
아래 그림은 다양한 예시의 그림자 제거 결과이다.

배경색이 그라데이션이 있는 즉, 하나의 지배적인 색이 없다면 실패할 수 있지만, 기존 방법도 동일하게 실패한다. 또한 문서가 완전히 그림자로 덮히거나 여러 조명에 의한 복잡한 그림자가 생기는 경우 실패할 수 있다.
아래의 (a)는 실제 이미지, (b)는 예상 배경색, (c)는 attention map, (d)는 이미지 복구 결과이다.

5.4. Evaluation on content preservation
188개의 이미지를 통해 OCR 성능을 평가한다. 아래 표와 같이 BECSR-Net이 문서의 구조 및 내용을 더 잘 보존하는 것을 확인할 수 있다 (distance가 낮을수록 OCR 성능이 좋다는 의미).

6. Conclusion
문서 이미지의 그림자 제거 모델 BEDSR-Net을 제안한다.
문서의 특징 속성을 탐색하기 위해 배경색 네트워크 BE-Net을 제안한다. 또한 shadow의 위치 표시를 위해 attention map을 생성한다.
추정 배경색과 attention map을 통해, 시각적 품질에서 SOTA를 달성하고 문서 이미지의 가독성을 향상시킨다.
다양한 문서 이미지를 사용하여 훈련하기 위해 합성 dataset을 사용하고 합성 dataset을 통해 학습된 모델이 실제 이미지에서도 잘 수행된다는 것을 보인다.
반응형